 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Budget Unsupervised Label Query through Domain Alignment Enforcement
Paper and Code
Jan 01, 2020
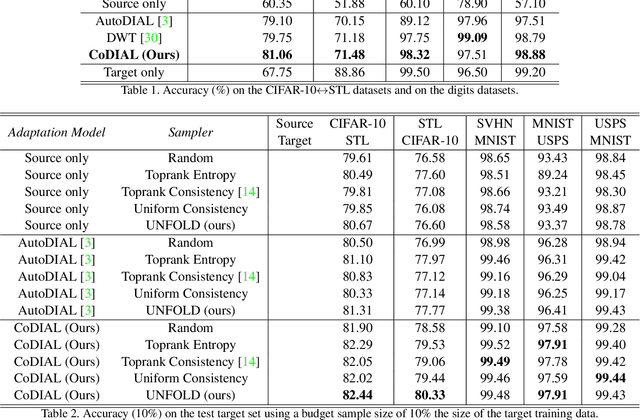


Deep learning revolution happened thanks to the availability of a massive amount of labelled data which have contributed to the development of models with extraordinary inference capabilities. Despite the public availability of a large quantity of datasets, it is often necessary to generate a new set of labelled data to address specific requirements. In addition, the production of labels is costly and sometimes it requires a specific expertise to be fulfilled. In this work, we introduce a new problem called low budget unsupervised label query that consists in a model trained to suggests to the user a set of samples to be labelled, from a completely unlabelled dataset, to maximize the classification accuracy on that dataset. We propose to adopt a domain alignment model, modified to enforce consistency, to align a known dataset (source) and the dataset to be labelled (target). Finally, we propose a novel sample selection method based on uniform entropy sampling, named UNFOLD, which is deterministic and steadily outperforms other baselines as well as competing models on a large variety of publicly available datasets.