 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossless CNN Channel Pruning via Gradient Resetting and Convolutional Re-parameterization
Paper and Code
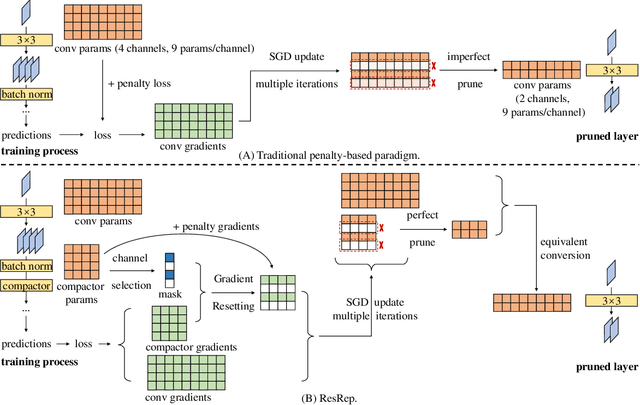
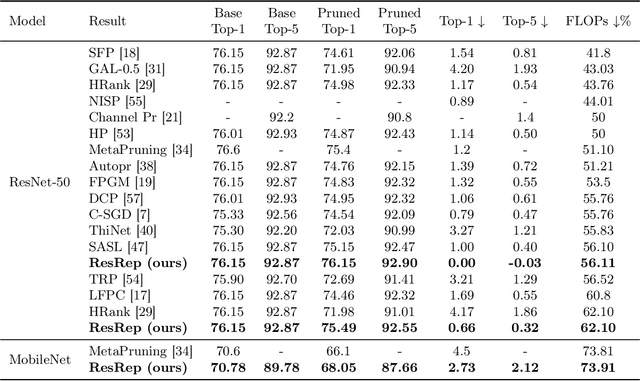
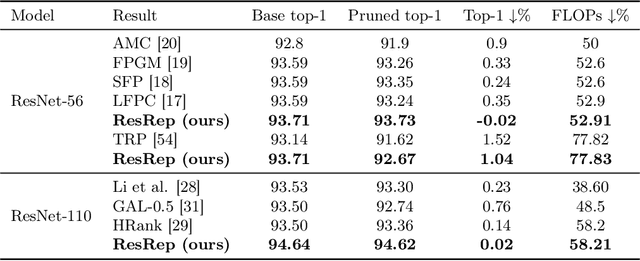

Channel pruning (a.k.a. filter pruning) aims to slim down a convolutional neural network (CNN) by reducing the width (i.e., numbers of output channels) of convolutional layers. However, as CNN's representational capacity depends on the width, doing so tends to degrade the performance. A traditional learning-based channel pruning paradigm applies a penalty on parameters to improve the robustness to pruning, but such a penalty may degrade the performance even before pruning. Inspired by the neurobiology research about the independence of remembering and forgetting, we propose to re-parameterize a CNN into the remembering parts and forgetting parts, where the former learn to maintain the performance and the latter learn for efficiency. By training the re-parameterized model using regular SGD on the former but a novel update rule with penalty gradients on the latter, we achieve structured sparsity, enabling us to equivalently convert the re-parameterized model into the original architecture with narrower layers. With our method, we can slim down a standard ResNet-50 with 76.15\% top-1 accuracy on ImageNet to a narrower one with only 43.9\% FLOPs and no accuracy drop. Code and models are released at https://github.com/DingXiaoH/ResRep.