 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Term Temporal Context for Per-Camera Object Detection
Paper and Code

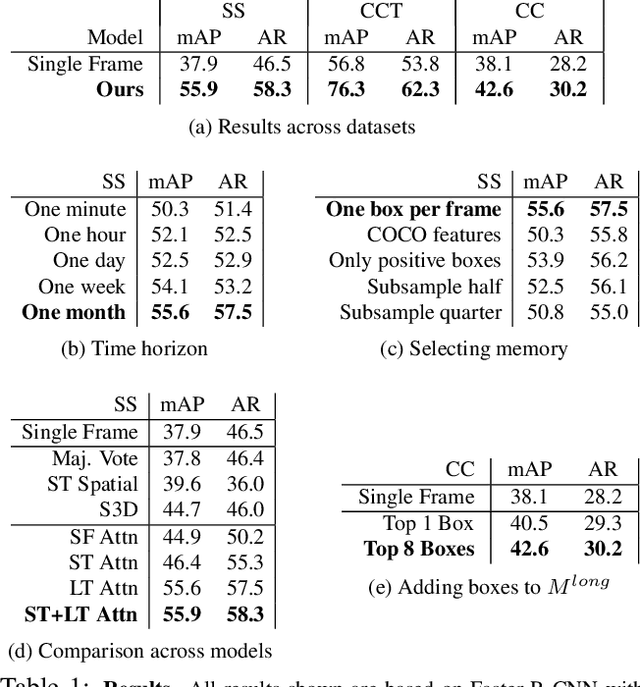

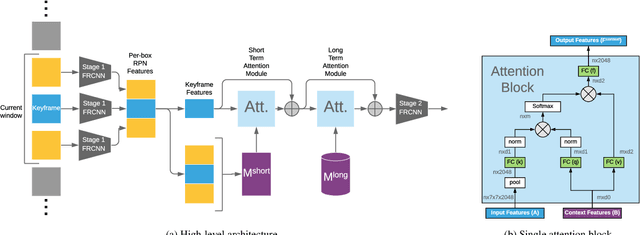
In static monitoring cameras, useful contextual information can stretch far beyond the few seconds typical video understanding models might see: subjects may exhibit similar behavior over multiple days, and background objects remain static. However, due to power and storage constraints, sampling frequencies are low, often no faster than one frame per second, and sometimes are irregular due to the use of a motion trigger. In order to perform well in this setting, models must be robust to irregular sampling rates. In this paper we propose an attention-based approach that allows our model to index into a long term memory bank constructed on a per-camera basis and aggregate contextual features from other frames to boost object detection performance on the current frame. We apply our models to two settings: (1) species detection using camera trap data, which is sampled at a low, variable frame rate based on a motion trigger and used to study biodiversity, and (2) vehicle detection in traffic cameras, which have similarly low frame rate. We show that our model leads to performance gains over strong baselines in all settings. Moreover, we show that increasing the time horizon for our memory bank leads to improved results. When applied to camera trap data from the Snapshot Serengeti dataset, our best model which leverages context from up to a month of images outperforms the single-frame baseline by 17.9% mAP at 0.5 IOU, and outperforms S3D (a 3d convolution based baseline) by 11.2% mAP.