 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-range gene expression prediction with token alignment of large language model
Paper and Code
Oct 02, 2024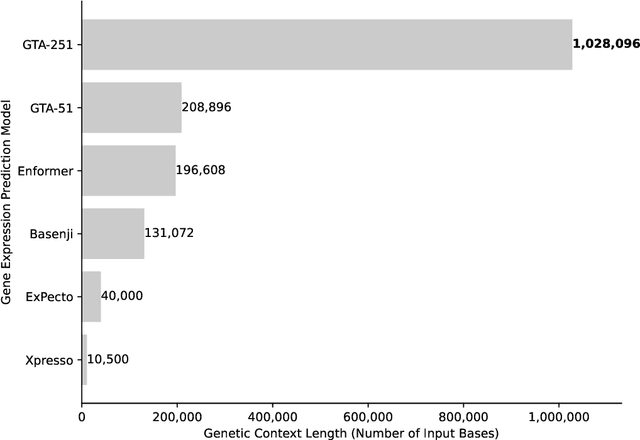
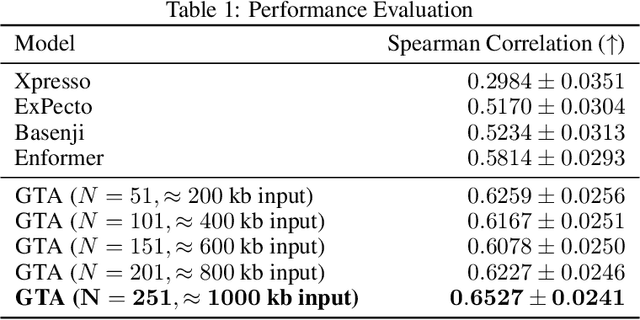
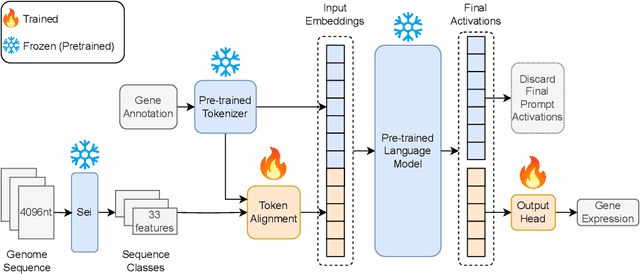

Gene expression is a cellular process that plays a fundamental role in human phenotypical variations and diseases. Despite advances of deep learning models for gene expression prediction, recent benchmarks have revealed their inability to learn distal regulatory grammar. Here, we address this challenge by leveraging a pretrained large language model to enhance gene expression prediction. We introduce Genetic sequence Token Alignment (GTA), which aligns genetic sequence features with natural language tokens, allowing for symbolic reasoning of genomic sequence features via the frozen language model. This cross-modal adaptation learns the regulatory grammar and allows us to further incorporate gene-specific human annotations as prompts, enabling in-context learning that is not possible with existing models. Trained on lymphoblastoid cells, GTA was evaluated on cells from the Geuvadis consortium and outperforms state-of-the-art models such as Enformer, achieving a Spearman correlation of 0.65, a 10\% improvement. Additionally, GTA offers improved interpretation of long-range interactions through the identification of the most meaningful sections of the input genetic context. GTA represents a powerful and novel cross-modal approach to gene expression prediction by utilizing a pretrained language model, in a paradigm shift from conventional gene expression models trained only on sequence data.