Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogarithmic Bayes Regret Bounds
Paper and Code
Jun 15, 2023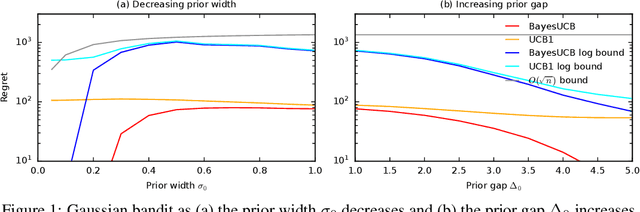
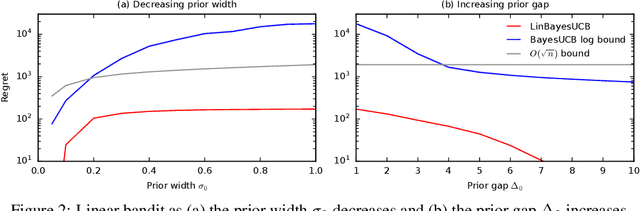
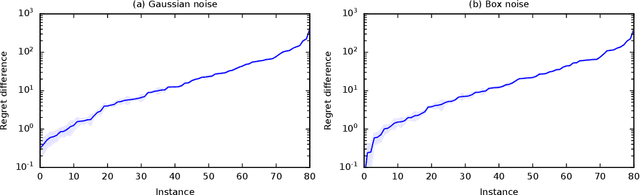
We derive the first finite-time logarithmic regret bounds for Bayesian bandits. For Gaussian bandits, we obtain a $O(c_h \log^2 n)$ bound, where $c_h$ is a prior-dependent constant. This matches the asymptotic lower bound of Lai (1987). Our proofs mark a technical departure from prior works, and are simple and general. To show generality, we apply our technique to linear bandits. Our bounds shed light on the value of the prior in the Bayesian setting, both in the objective and as a side information given to the learner. They significantly improve the $\tilde{O}(\sqrt{n})$ bounds, that despite the existing lower bounds, have become standard in the literature.
View paper on