 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation-Free Scene Graph Generation
Paper and Code
Mar 20, 2023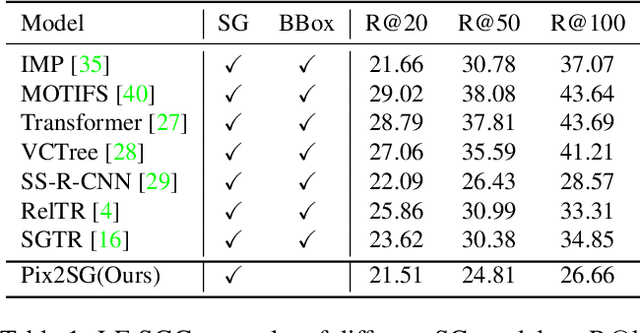
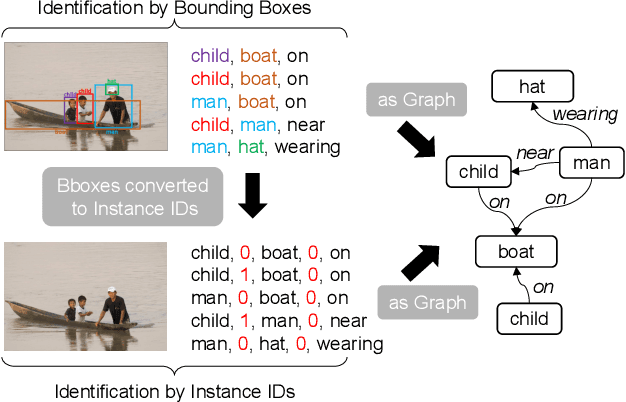
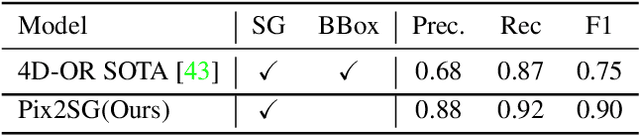
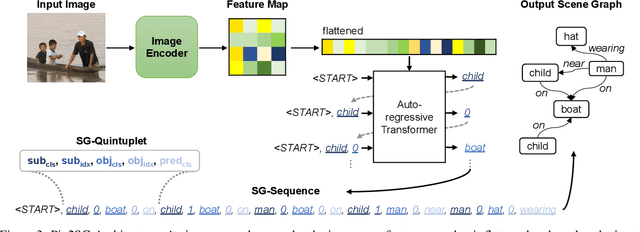
Scene Graph Generation (SGG) is a challenging visual understanding task. It combines the detection of entities and relationships between them in a scene. Both previous works and existing evaluation metrics rely on bounding box labels, even though many downstream scene graph applications do not need location information. The need for localization labels significantly increases the annotation cost and hampers the creation of more and larger scene graph datasets. We suggest breaking the dependency of scene graphs on bounding box labels by proposing location-free scene graph generation (LF-SGG). This new task aims at predicting instances of entities, as well as their relationships, without spatial localization. To objectively evaluate the task, the predicted and ground truth scene graphs need to be compared. We solve this NP-hard problem through an efficient algorithm using branching. Additionally, we design the first LF-SGG method, Pix2SG, using autoregressive sequence modeling. Our proposed method is evaluated on Visual Genome and 4D-OR. Although using significantly fewer labels during training, we achieve 74.12\% of the location-supervised SOTA performance on Visual Genome and even outperform the best method on 4D-OR.