 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLM2D: Lyrics- and Music-Driven Dance Synthesis
Paper and Code
Mar 14, 2024
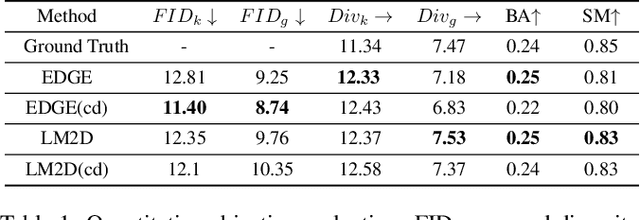
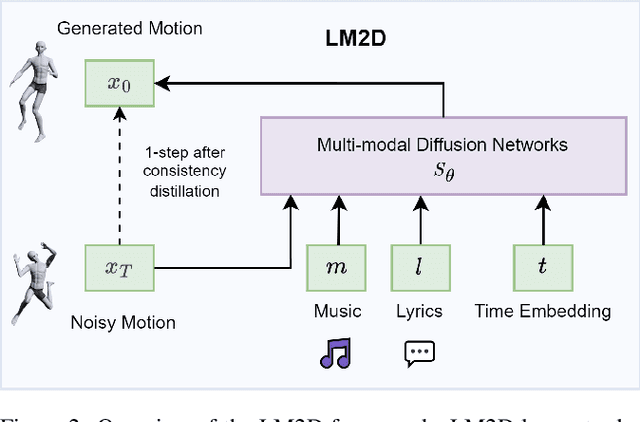
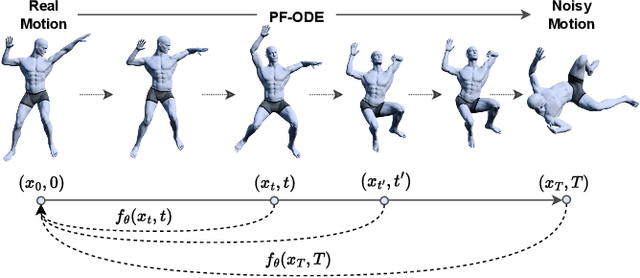
Dance typically involves professional choreography with complex movements that follow a musical rhythm and can also be influenced by lyrical content. The integration of lyrics in addition to the auditory dimension, enriches the foundational tone and makes motion generation more amenable to its semantic meanings. However, existing dance synthesis methods tend to model motions only conditioned on audio signals. In this work, we make two contributions to bridge this gap. First, we propose LM2D, a novel probabilistic architecture that incorporates a multimodal diffusion model with consistency distillation, designed to create dance conditioned on both music and lyrics in one diffusion generation step. Second, we introduce the first 3D dance-motion dataset that encompasses both music and lyrics, obtained with pose estimation technologies. We evaluate our model against music-only baseline models with objective metrics and human evaluations, including dancers and choreographers. The results demonstrate LM2D is able to produce realistic and diverse dance matching both lyrics and music. A video summary can be accessed at: https://youtu.be/4XCgvYookvA.