 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListing Maximal k-Plexes in Large Real-World Graphs
Paper and Code
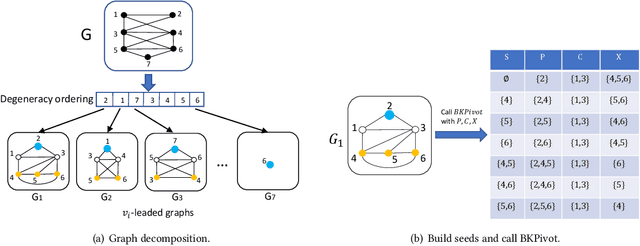
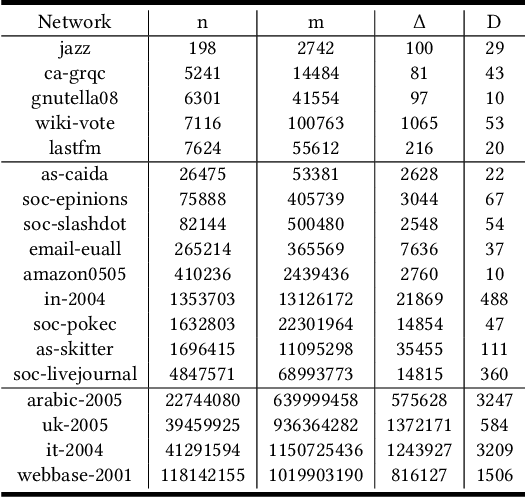
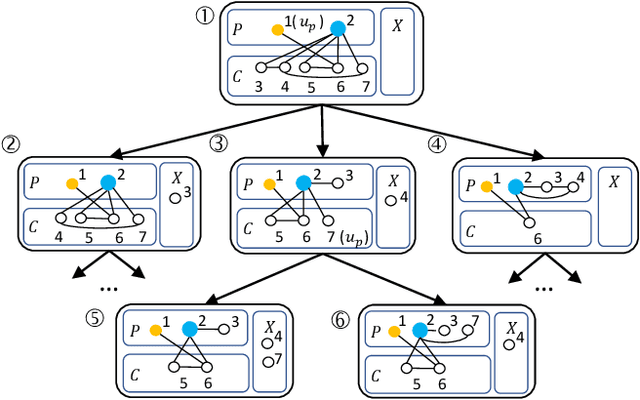
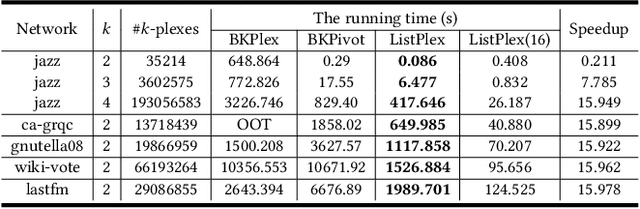
Listing dense subgraphs in large graphs plays a key task in varieties of network analysis applications like community detection. Clique, as the densest model, has been widely investigated. However, in practice, communities rarely form as cliques for various reasons, e.g., data noise. Therefore, $k$-plex, -- graph with each vertex adjacent to all but at most $k$ vertices, is introduced as a relaxed version of clique. Often, to better simulate cohesive communities, an emphasis is placed on connected $k$-plexes with small $k$. In this paper, we continue the research line of listing all maximal $k$-plexes and maximal $k$-plexes of prescribed size. Our first contribution is algorithm ListPlex that lists all maximal $k$-plexes in $O^*(\gamma^D)$ time for each constant $k$, where $\gamma$ is a value related to $k$ but strictly smaller than 2, and $D$ is the degeneracy of the graph that is far less than the vertex number $n$ in real-word graphs. Compared to the trivial bound of $2^n$, the improvement is significant, and our bound is better than all previously known results. In practice, we further use several techniques to accelerate listing $k$-plexes of a given size, such as structural-based prune rules, cache-efficient data structures, and parallel techniques. All these together result in a very practical algorithm. Empirical results show that our approach outperforms the state-of-the-art solutions by up to orders of magnitude.