 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search
Paper and Code
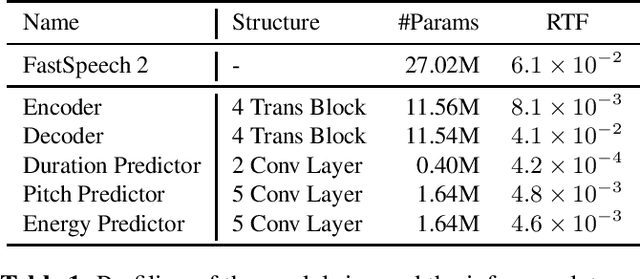
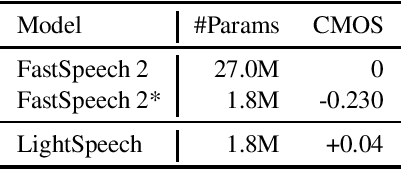

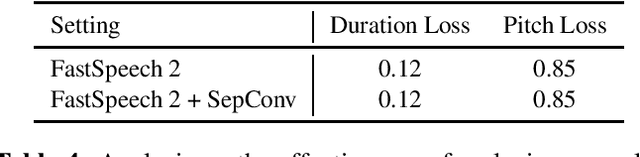
Text to speech (TTS) has been broadly used to synthesize natural and intelligible speech in different scenarios. Deploying TTS in various end devices such as mobile phones or embedded devices requires extremely small memory usage and inference latency. While non-autoregressive TTS models such as FastSpeech have achieved significantly faster inference speed than autoregressive models, their model size and inference latency are still large for the deployment in resource constrained devices. In this paper, we propose LightSpeech, which leverages neural architecture search~(NAS) to automatically design more lightweight and efficient models based on FastSpeech. We first profile the components of current FastSpeech model and carefully design a novel search space containing various lightweight and potentially effective architectures. Then NAS is utilized to automatically discover well performing architectures within the search space. Experiments show that the model discovered by our method achieves 15x model compression ratio and 6.5x inference speedup on CPU with on par voice quality. Audio demos are provided at https://speechresearch.github.io/lightspeech.