 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeast Squares Regression with Markovian Data: Fundamental Limits and Algorithms
Paper and Code
Jun 16, 2020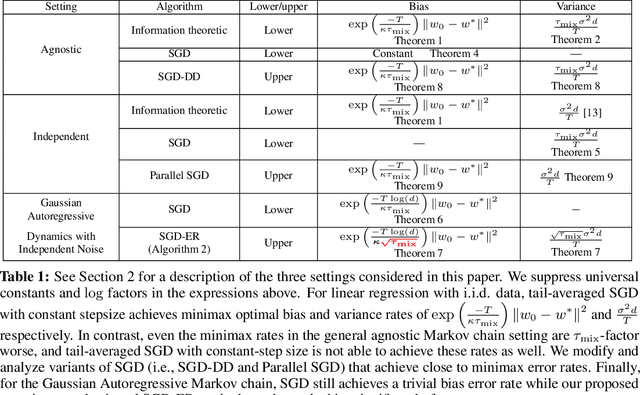
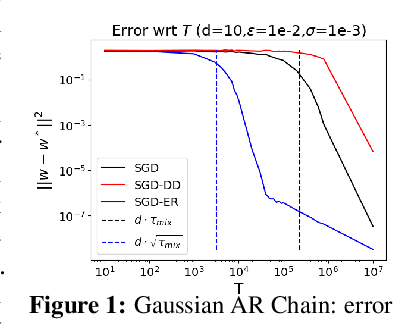
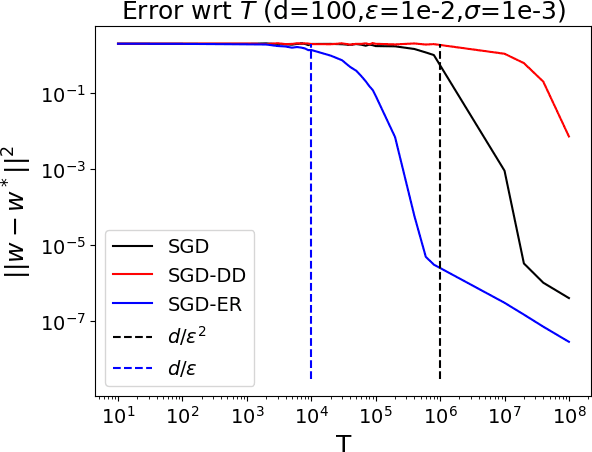
We study the problem of least squares linear regression where the data-points are dependent and are sampled from a Markov chain. We establish sharp information theoretic minimax lower bounds for this problem in terms of $\tau_{\mathsf{mix}}$, the mixing time of the underlying Markov chain, under different noise settings. Our results establish that in general, optimization with Markovian data is strictly harder than optimization with independent data and a trivial algorithm (SGD-DD) that works with only one in every $\tilde{\Theta}(\tau_{\mathsf{mix}})$ samples, which are approximately independent, is minimax optimal. In fact, it is strictly better than the popular Stochastic Gradient Descent (SGD) method with constant step-size which is otherwise minimax optimal in the regression with independent data setting. Beyond a worst case analysis, we investigate whether structured datasets seen in practice such as Gaussian auto-regressive dynamics can admit more efficient optimization schemes. Surprisingly, even in this specific and natural setting, Stochastic Gradient Descent (SGD) with constant step-size is still no better than SGD-DD. Instead, we propose an algorithm based on experience replay--a popular reinforcement learning technique--that achieves a significantly better error rate. Our improved rate serves as one of the first results where an algorithm outperforms SGD-DD on an interesting Markov chain and also provides one of the first theoretical analyses to support the use of experience replay in practice.