Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to superoptimize programs - Workshop Version
Paper and Code
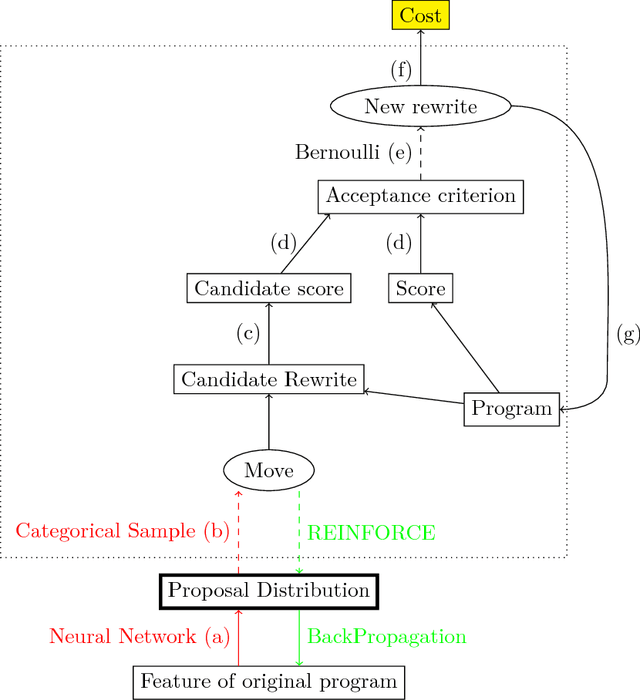
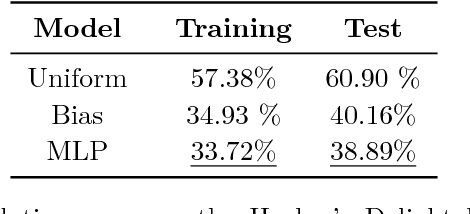
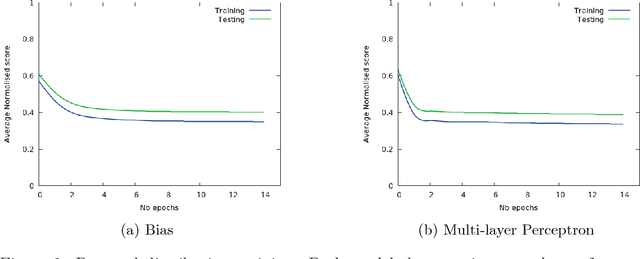
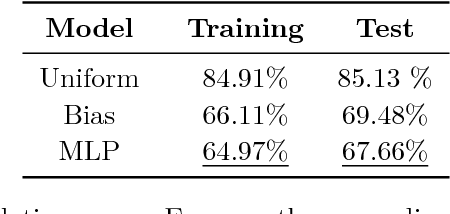
Superoptimization requires the estimation of the best program for a given computational task. In order to deal with large programs, superoptimization techniques perform a stochastic search. This involves proposing a modification of the current program, which is accepted or rejected based on the improvement achieved. The state of the art method uses uniform proposal distributions, which fails to exploit the problem structure to the fullest. To alleviate this deficiency, we learn a proposal distribution over possible modifications using Reinforcement Learning. We provide convincing results on the superoptimization of "Hacker's Delight" programs.
* Workshop version for the NIPS NAMPI Workshop. Extended version at
arXiv:1611.01787
View paper on