 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-to-Rank with Partitioned Preference: Fast Estimation for the Plackett-Luce Model
Paper and Code
Jun 09, 2020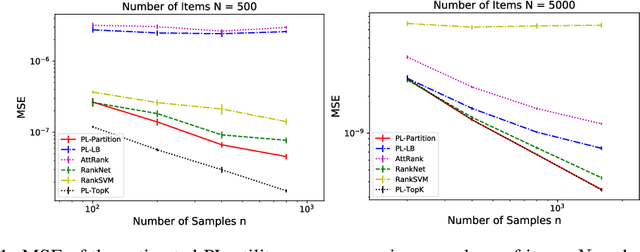
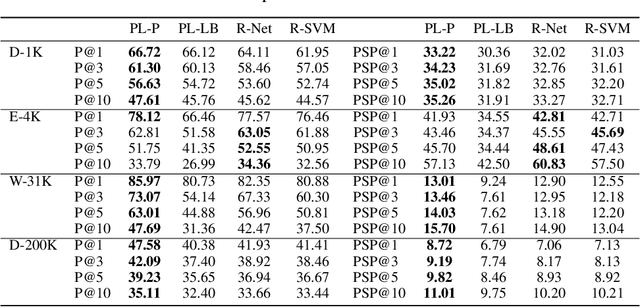
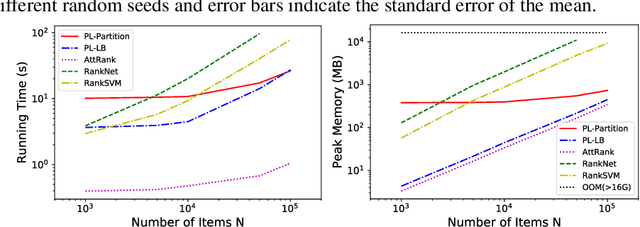
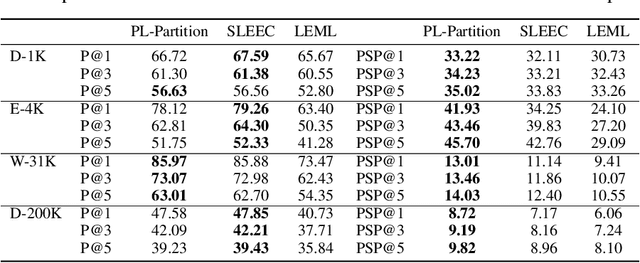
We consider the problem of listwise learning-to-rank (LTR) on data with \textit{partitioned preference}, where a set of items are sliced into ordered and disjoint partitions, but the ranking of items within a partition is unknown. The Plackett-Luce (PL) model has been widely used in listwise LTR methods. However, given $N$ items with $M$ partitions, calculating the likelihood of data with partitioned preference under the PL model has a time complexity of $O(N+S!)$, where $S$ is the maximum size of the top $M-1$ partitions. This computational challenge restrains existing PL-based listwise LTR methods to only a special case of partitioned preference, \textit{top-$K$ ranking}, where the exact order of the top $K$ items is known. In this paper, we exploit a random utility model formulation of the PL model and propose an efficient approach through numerical integration for calculating the likelihood. This numerical approach reduces the aforementioned time complexity to $O(N+MS)$, which allows training deep-neural-network-based ranking models with a large output space. We demonstrate that the proposed method outperforms well-known LTR baselines and remains scalable through both simulation experiments and applications to real-world eXtreme Multi-Label (XML) classification tasks. The proposed method also achieves state-of-the-art performance on XML datasets with relatively large numbers of labels per sample.