 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Cope with Adversarial Attacks
Paper and Code
Jun 28, 2019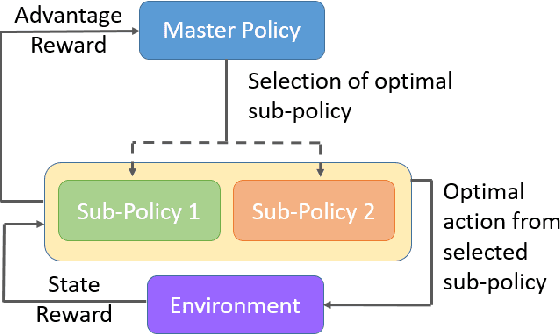
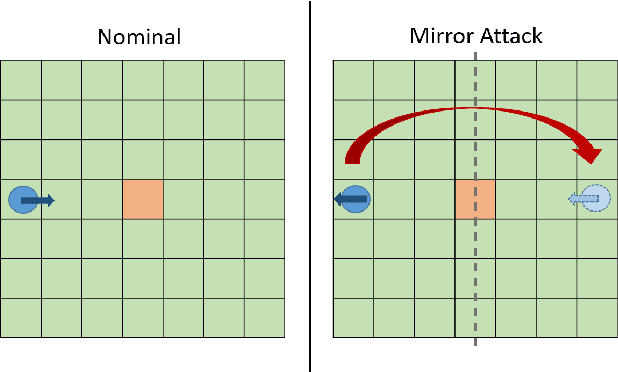
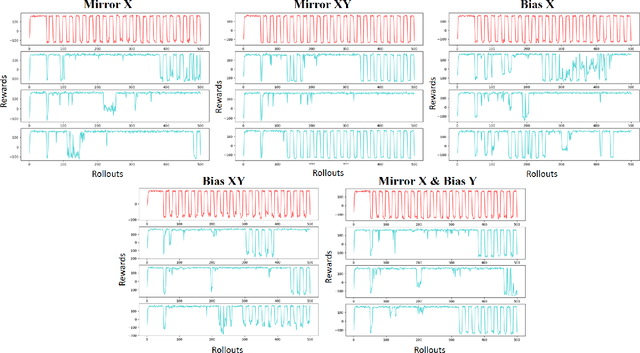
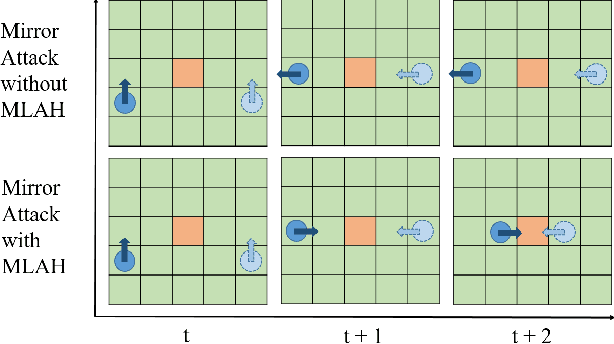
The security of Deep Reinforcement Learning (Deep RL) algorithms deployed in real life applications are of a primary concern. In particular, the robustness of RL agents in cyber-physical systems against adversarial attacks are especially vital since the cost of a malevolent intrusions can be extremely high. Studies have shown Deep Neural Networks (DNN), which forms the core decision-making unit in most modern RL algorithms, are easily subjected to adversarial attacks. Hence, it is imperative that RL agents deployed in real-life applications have the capability to detect and mitigate adversarial attacks in an online fashion. An example of such a framework is the Meta-Learned Advantage Hierarchy (MLAH) agent that utilizes a meta-learning framework to learn policies robustly online. Since the mechanism of this framework are still not fully explored, we conducted multiple experiments to better understand the framework's capabilities and limitations. Our results shows that the MLAH agent exhibits interesting coping behaviors when subjected to different adversarial attacks to maintain a nominal reward. Additionally, the framework exhibits a hierarchical coping capability, based on the adaptability of the Master policy and sub-policies themselves. From empirical results, we also observed that as the interval of adversarial attacks increase, the MLAH agent can maintain a higher distribution of rewards, though at the cost of higher instabilities.