 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Structure of Generative Models without Labeled Data
Paper and Code
Sep 09, 2017

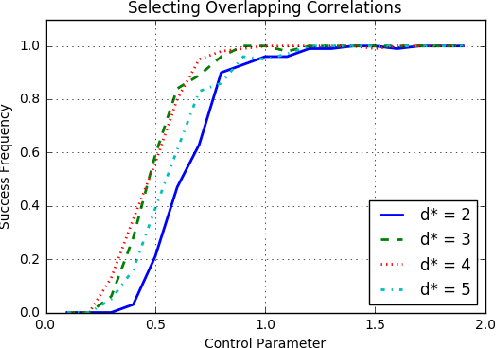

Curating labeled training data has become the primary bottleneck in machine learning. Recent frameworks address this bottleneck with generative models to synthesize labels at scale from weak supervision sources. The generative model's dependency structure directly affects the quality of the estimated labels, but selecting a structure automatically without any labeled data is a distinct challenge. We propose a structure estimation method that maximizes the $\ell_1$-regularized marginal pseudolikelihood of the observed data. Our analysis shows that the amount of unlabeled data required to identify the true structure scales sublinearly in the number of possible dependencies for a broad class of models. Simulations show that our method is 100$\times$ faster than a maximum likelihood approach and selects $1/4$ as many extraneous dependencies. We also show that our method provides an average of 1.5 F1 points of improvement over existing, user-developed information extraction applications on real-world data such as PubMed journal abstracts.