 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multiple Defaults for Machine Learning Algorithms
Paper and Code
Nov 23, 2018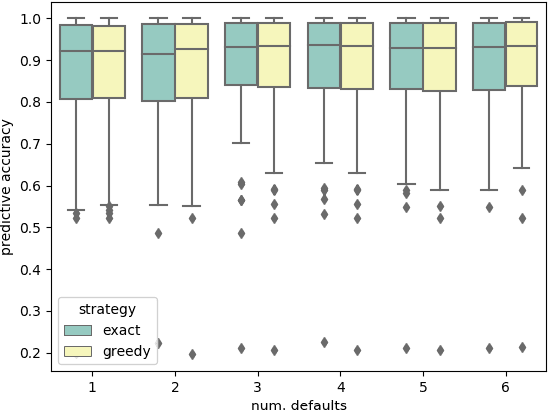
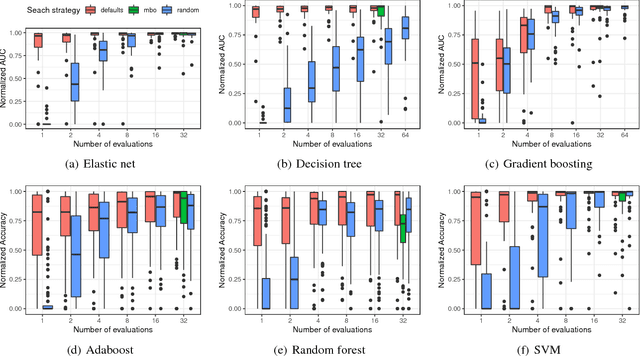
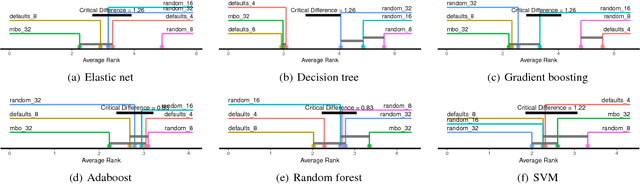
The performance of modern machine learning methods highly depends on their hyperparameter configurations. One simple way of selecting a configuration is to use default settings, often proposed along with the publication and implementation of a new algorithm. Those default values are usually chosen in an ad-hoc manner to work good enough on a wide variety of datasets. To address this problem, different automatic hyperparameter configuration algorithms have been proposed, which select an optimal configuration per dataset. This principled approach usually improves performance, but adds additional algorithmic complexity and computational costs to the training procedure. As an alternative to this, we propose learning a set of complementary default values from a large database of prior empirical results. Selecting an appropriate configuration on a new dataset then requires only a simple, efficient and embarrassingly parallel search over this set. We demonstrate the effectiveness and efficiency of the approach we propose in comparison to random search and Bayesian Optimization.