 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Light-Weight Translation Models from Deep Transformer
Paper and Code

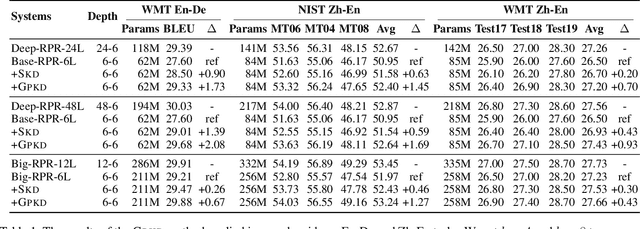

Recently, deep models have shown tremendous improvements in neural machine translation (NMT). However, systems of this kind are computationally expensive and memory intensive. In this paper, we take a natural step towards learning strong but light-weight NMT systems. We proposed a novel group-permutation based knowledge distillation approach to compressing the deep Transformer model into a shallow model. The experimental results on several benchmarks validate the effectiveness of our method. Our compressed model is 8X shallower than the deep model, with almost no loss in BLEU. To further enhance the teacher model, we present a Skipping Sub-Layer method to randomly omit sub-layers to introduce perturbation into training, which achieves a BLEU score of 30.63 on English-German newstest2014. The code is publicly available at https://github.com/libeineu/GPKD.