 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Grasp Affordance Reasoning through Semantic Relations
Paper and Code
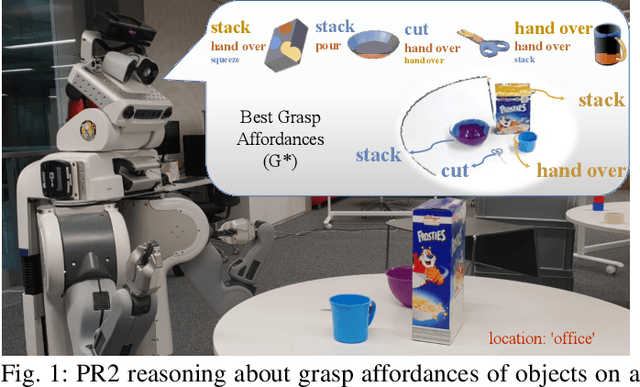
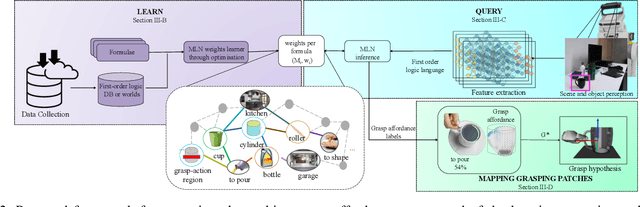
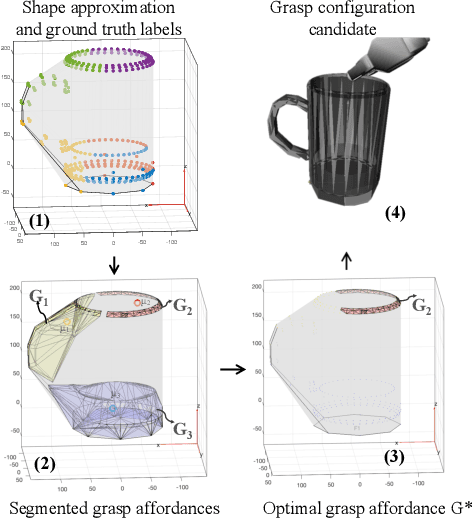
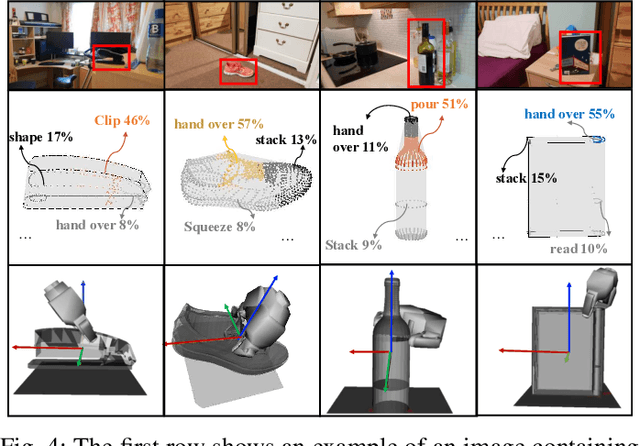
Reasoning about object affordances allows an autonomous agent to perform generalised manipulation tasks among object instances. While current approaches to grasp affordance estimation are effective, they are limited to a single hypothesis. We present an approach for detection and extraction of multiple grasp affordances on an object via visual input. We define semantics as a combination of multiple attributes, which yields benefits in terms of generalisation for grasp affordance prediction. We use Markov Logic Networks to build a knowledge base graph representation to obtain a probability distribution of grasp affordances for an object. To harvest the knowledge base, we collect and make available a novel dataset that relates different semantic attributes. We achieve reliable mappings of the predicted grasp affordances on the object by learning prototypical grasping patches from several examples. We show our method's generalisation capabilities on grasp affordance prediction for novel instances and compare with similar methods in the literature. Moreover, using a robotic platform, on simulated and real scenarios, we evaluate the success of the grasping task when conditioned on the grasp affordance prediction.