 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Comparisons and Choices
Paper and Code
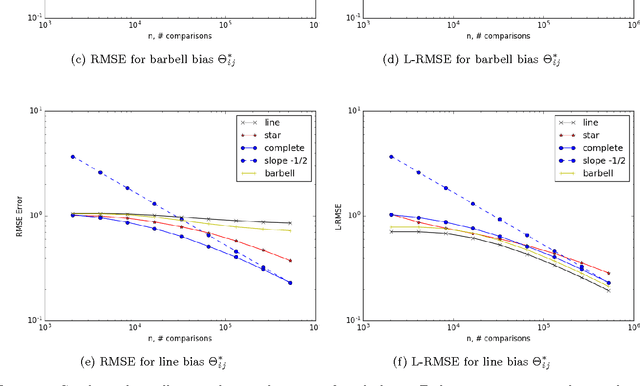
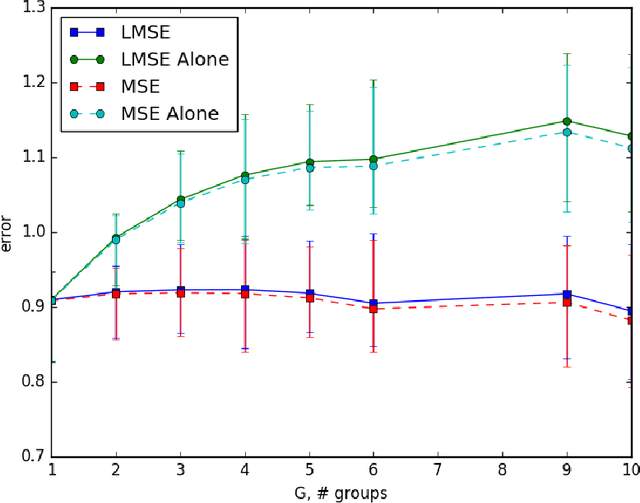
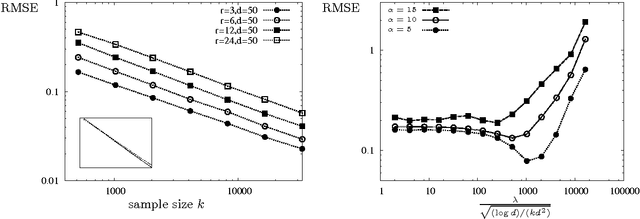
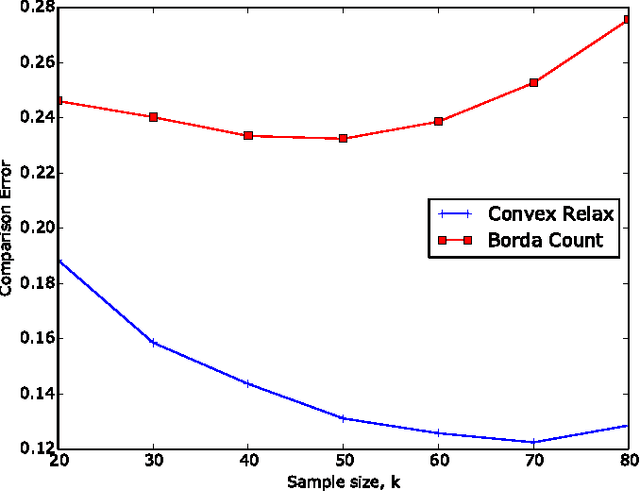
When tracking user-specific online activities, each user's preference is revealed in the form of choices and comparisons. For example, a user's purchase history tracks her choices, i.e. which item was chosen among a subset of offerings. A user's comparisons are observed either explicitly as in movie ratings or implicitly as in viewing times of news articles. Given such individualized ordinal data, we address the problem of collaboratively learning representations of the users and the items. The learned features can be used to predict a user's preference of an unseen item to be used in recommendation systems. This also allows one to compute similarities among users and items to be used for categorization and search. Motivated by the empirical successes of the MultiNomial Logit (MNL) model in marketing and transportation, and also more recent successes in word embedding and crowdsourced image embedding, we pose this problem as learning the MNL model parameters that best explains the data. We propose a convex optimization for learning the MNL model, and show that it is minimax optimal up to a logarithmic factor by comparing its performance to a fundamental lower bound. This characterizes the minimax sample complexity of the problem, and proves that the proposed estimator cannot be improved upon other than by a logarithmic factor. Further, the analysis identifies how the accuracy depends on the topology of sampling via the spectrum of the sampling graph. This provides a guideline for designing surveys when one can choose which items are to be compared. This is accompanies by numerical simulations on synthetic and real datasets confirming our theoretical predictions.