 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Equational Theorem Proving
Paper and Code
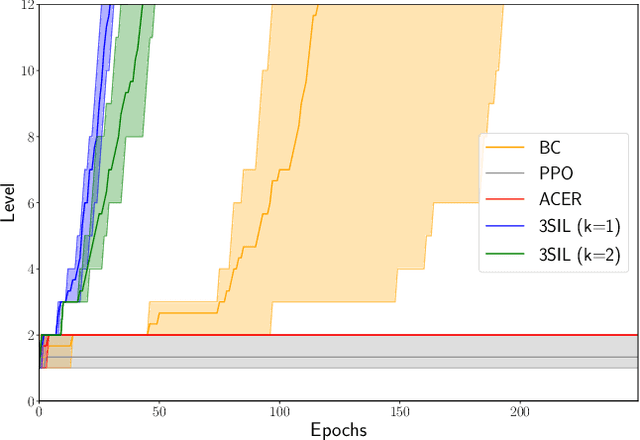
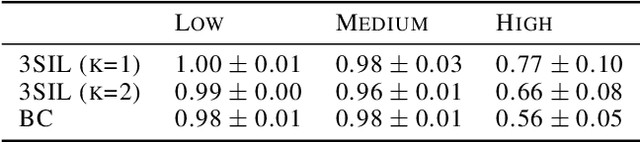
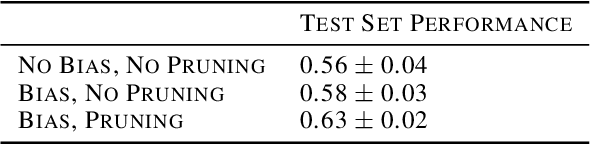
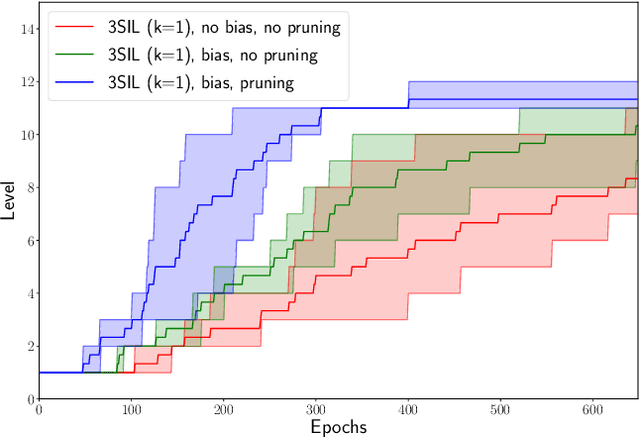
We develop Stratified Shortest Solution Imitation Learning (3SIL) to learn equational theorem proving in a deep reinforcement learning (RL) setting. The self-trained models achieve state-of-the-art performance in proving problems generated by one of the top open conjectures in quasigroup theory, the Abelian Inner Mapping (AIM) Conjecture. To develop the methods, we first use two simpler arithmetic rewriting tasks that share tree-structured proof states and sparse rewards with the AIM problems. On these tasks, 3SIL is shown to significantly outperform several established RL and imitation learning methods. The final system is then evaluated in a standalone and cooperative mode on the AIM problems. The standalone 3SIL-trained system proves in 60 seconds more theorems (70.2%) than the complex, hand-engineered Waldmeister system (65.5%). In the cooperative mode, the final system is combined with the Prover9 system, proving in 2 seconds what standalone Prover9 proves in 60 seconds.