 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned 3D Shape Representations Using Fused Geometrically Augmented Images: Application to Facial Expression and Action Unit Detection
Paper and Code
Apr 08, 2019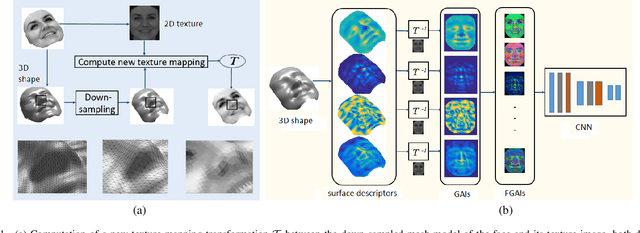



This paper proposes an approach to learn generic multi-modal mesh surface representations using a novel scheme for fusing texture and geometric data. Our approach defines an inverse mapping between different geometric descriptors computed on the mesh surface or its down-sampled version, and the corresponding 2D texture image of the mesh, allowing the construction of fused geometrically augmented images (FGAI). This new fused modality enables us to learn feature representations from 3D data in a highly efficient manner by simply employing standard convolutional neural networks in a transfer-learning mode. In contrast to existing methods, the proposed approach is both computationally and memory efficient, preserves intrinsic geometric information and learns highly discriminative feature representation by effectively fusing shape and texture information at data level. The efficacy of our approach is demonstrated for the tasks of facial action unit detection and expression classification. The extensive experiments conducted on the Bosphorus and BU-4DFE datasets, show that our method produces a significant boost in the performance when compared to state-of-the-art solutions