 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCrowdV: Generating Labeled Videos for Simulation-based Crowd Behavior Learning
Paper and Code
Jul 04, 2016
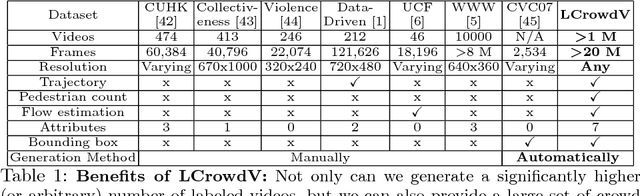
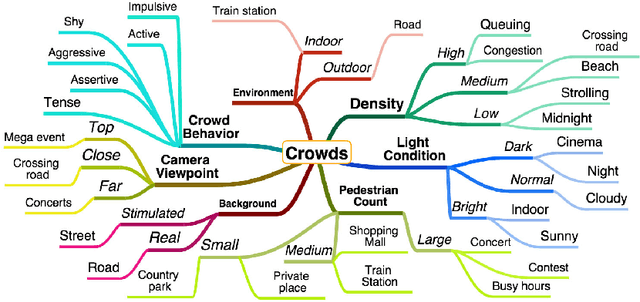
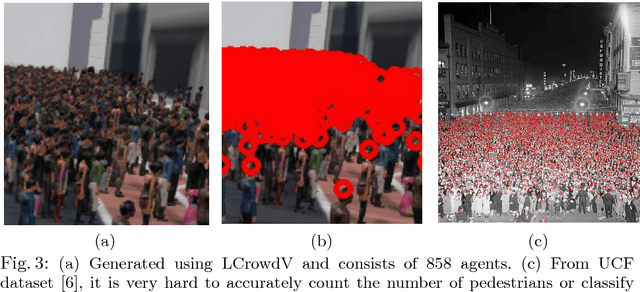
We present a novel procedural framework to generate an arbitrary number of labeled crowd videos (LCrowdV). The resulting crowd video datasets are used to design accurate algorithms or training models for crowded scene understanding. Our overall approach is composed of two components: a procedural simulation framework for generating crowd movements and behaviors, and a procedural rendering framework to generate different videos or images. Each video or image is automatically labeled based on the environment, number of pedestrians, density, behavior, flow, lighting conditions, viewpoint, noise, etc. Furthermore, we can increase the realism by combining synthetically-generated behaviors with real-world background videos. We demonstrate the benefits of LCrowdV over prior lableled crowd datasets by improving the accuracy of pedestrian detection and crowd behavior classification algorithms. LCrowdV would be released on the WWW.