 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLattice Long Short-Term Memory for Human Action Recognition
Paper and Code
Aug 13, 2017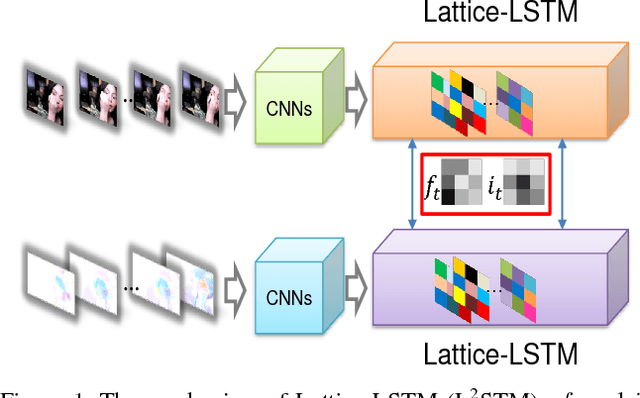
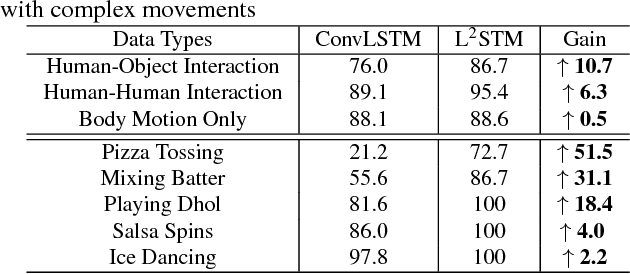
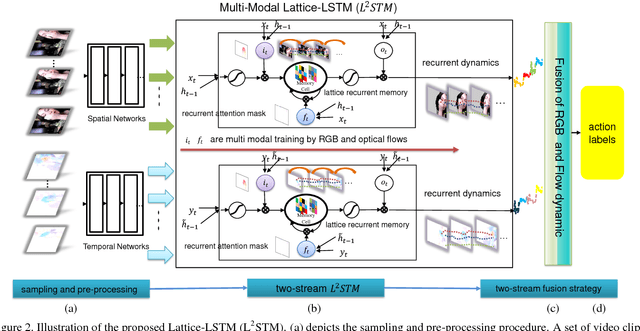
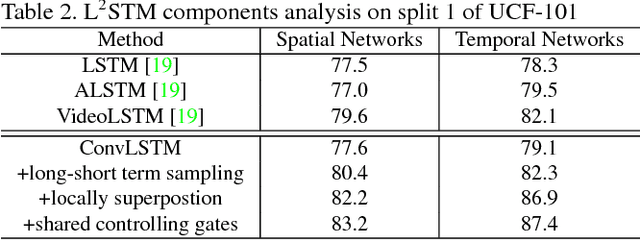
Human actions captured in video sequences are three-dimensional signals characterizing visual appearance and motion dynamics. To learn action patterns, existing methods adopt Convolutional and/or Recurrent Neural Networks (CNNs and RNNs). CNN based methods are effective in learning spatial appearances, but are limited in modeling long-term motion dynamics. RNNs, especially Long Short-Term Memory (LSTM), are able to learn temporal motion dynamics. However, naively applying RNNs to video sequences in a convolutional manner implicitly assumes that motions in videos are stationary across different spatial locations. This assumption is valid for short-term motions but invalid when the duration of the motion is long. In this work, we propose Lattice-LSTM (L2STM), which extends LSTM by learning independent hidden state transitions of memory cells for individual spatial locations. This method effectively enhances the ability to model dynamics across time and addresses the non-stationary issue of long-term motion dynamics without significantly increasing the model complexity. Additionally, we introduce a novel multi-modal training procedure for training our network. Unlike traditional two-stream architectures which use RGB and optical flow information as input, our two-stream model leverages both modalities to jointly train both input gates and both forget gates in the network rather than treating the two streams as separate entities with no information about the other. We apply this end-to-end system to benchmark datasets (UCF-101 and HMDB-51) of human action recognition. Experiments show that on both datasets, our proposed method outperforms all existing ones that are based on LSTM and/or CNNs of similar model complexities.