 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Autonomous Driving Scenarios Clustering with Self-supervised Feature Extraction
Paper and Code
Mar 30, 2021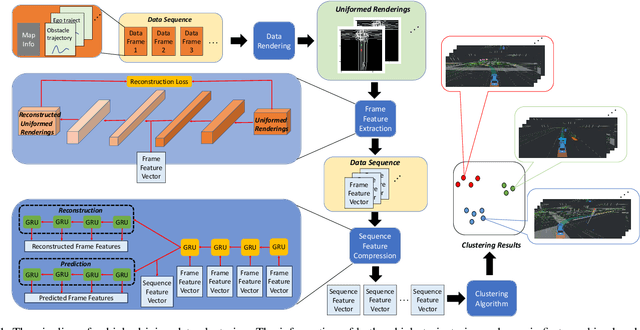
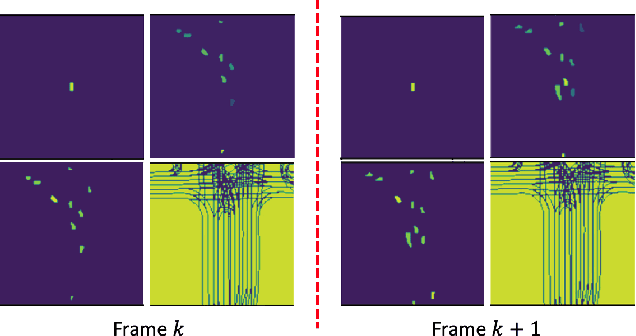
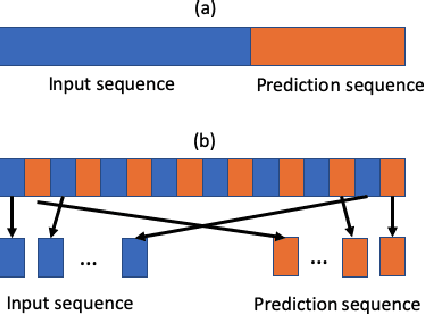
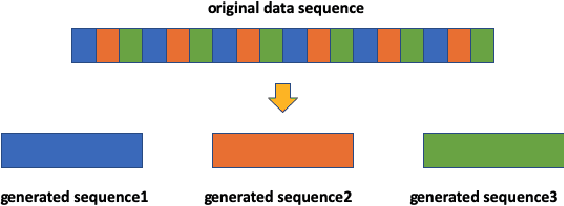
The clustering of autonomous driving scenario data can substantially benefit the autonomous driving validation and simulation systems by improving the simulation tests' completeness and fidelity. This article proposes a comprehensive data clustering framework for a large set of vehicle driving data. Existing algorithms utilize handcrafted features whose quality relies on the judgments of human experts. Additionally, the related feature compression methods are not scalable for a large data-set. Our approach thoroughly considers the traffic elements, including both in-traffic agent objects and map information. Meanwhile, we proposed a self-supervised deep learning approach for spatial and temporal feature extraction to avoid biased data representation. With the newly designed driving data clustering evaluation metrics based on data-augmentation, the accuracy assessment does not require a human-labeled data-set, which is subject to human bias. Via such unprejudiced evaluation metrics, we have shown our approach surpasses the existing methods that rely on handcrafted feature extractions.