 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Guided Domain Generalized Medical Image Segmentation
Paper and Code
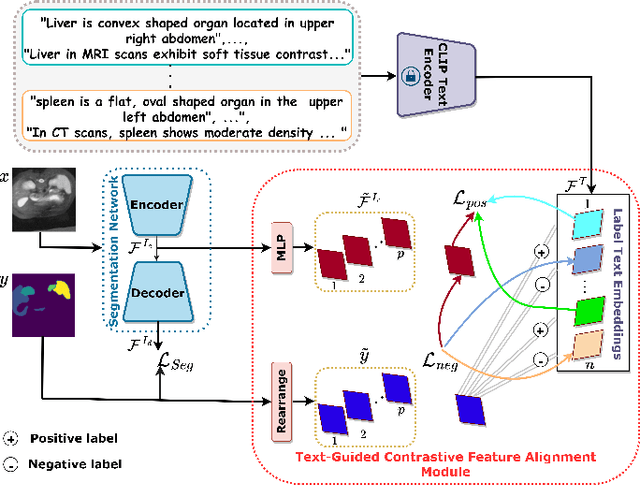



Single source domain generalization (SDG) holds promise for more reliable and consistent image segmentation across real-world clinical settings particularly in the medical domain, where data privacy and acquisition cost constraints often limit the availability of diverse datasets. Depending solely on visual features hampers the model's capacity to adapt effectively to various domains, primarily because of the presence of spurious correlations and domain-specific characteristics embedded within the image features. Incorporating text features alongside visual features is a potential solution to enhance the model's understanding of the data, as it goes beyond pixel-level information to provide valuable context. Textual cues describing the anatomical structures, their appearances, and variations across various imaging modalities can guide the model in domain adaptation, ultimately contributing to more robust and consistent segmentation. In this paper, we propose an approach that explicitly leverages textual information by incorporating a contrastive learning mechanism guided by the text encoder features to learn a more robust feature representation. We assess the effectiveness of our text-guided contrastive feature alignment technique in various scenarios, including cross-modality, cross-sequence, and cross-site settings for different segmentation tasks. Our approach achieves favorable performance against existing methods in literature. Our code and model weights are available at https://github.com/ShahinaKK/LG_SDG.git.