 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions
Paper and Code
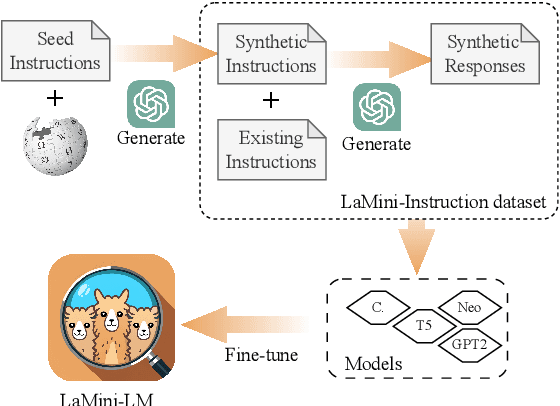



Large language models (LLMs) with instruction finetuning demonstrate superior generative capabilities. However, these models are resource intensive. To alleviate this issue, we explore distilling knowledge from instruction-tuned LLMs to much smaller ones. To this end, we carefully develop a large set of 2.58M instructions based on both existing and newly-generated instructions. In addition to being sizeable, we design our instructions to cover a broad set of topics to ensure. A thorough investigation of our instruction data demonstrate their diversity, and we generate responses for these instructions using gpt-3.5-turbo. We then exploit the instructions to tune a host of models, dubbed LaMini-LM, of varying sizes, both from the encoder-decoder as well as the decoder-only families. We evaluate our models both automatically (on 15 different NLP benchmarks) and manually. Results show that our proposed LaMini-LM are on par with competitive baselines while being nearly 10 times smaller in size.