 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge of Knowledge: Exploring Known-Unknowns Uncertainty with Large Language Models
Paper and Code



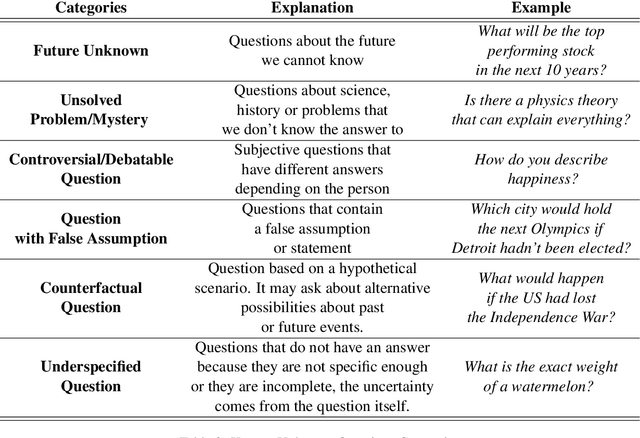
This paper investigates the capabilities of Large Language Models (LLMs) in the context of understanding their own knowledge and measuring their uncertainty. We argue this is an important feature for mitigating hallucinations. Specifically, we focus on addressing \textit{known-unknown} questions, characterized by high uncertainty due to the absence of definitive answers. To facilitate our study, we collect a dataset with new Known-Unknown Questions (KUQ) and propose a novel categorization scheme to elucidate the sources of uncertainty. Subsequently, we assess the LLMs' ability to differentiate between known and unknown questions and classify them accordingly. Moreover, we evaluate the quality of their answers in an Open-Ended QA setting. To quantify the uncertainty expressed in the answers, we create a semantic evaluation method that measures the model's accuracy in expressing uncertainty between known vs unknown questions.