 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnockoff-Guided Feature Selection via A Single Pre-trained Reinforced Agent
Paper and Code

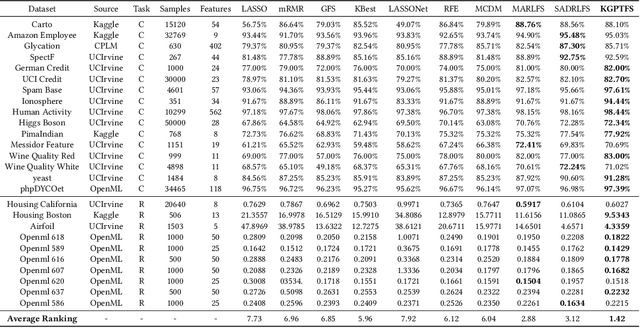


Feature selection prepares the AI-readiness of data by eliminating redundant features. Prior research falls into two primary categories: i) Supervised Feature Selection, which identifies the optimal feature subset based on their relevance to the target variable; ii) Unsupervised Feature Selection, which reduces the feature space dimensionality by capturing the essential information within the feature set instead of using target variable. However, SFS approaches suffer from time-consuming processes and limited generalizability due to the dependence on the target variable and downstream ML tasks. UFS methods are constrained by the deducted feature space is latent and untraceable. To address these challenges, we introduce an innovative framework for feature selection, which is guided by knockoff features and optimized through reinforcement learning, to identify the optimal and effective feature subset. In detail, our method involves generating "knockoff" features that replicate the distribution and characteristics of the original features but are independent of the target variable. Each feature is then assigned a pseudo label based on its correlation with all the knockoff features, serving as a novel metric for feature evaluation. Our approach utilizes these pseudo labels to guide the feature selection process in 3 novel ways, optimized by a single reinforced agent: 1). A deep Q-network, pre-trained with the original features and their corresponding pseudo labels, is employed to improve the efficacy of the exploration process in feature selection. 2). We introduce unsupervised rewards to evaluate the feature subset quality based on the pseudo labels and the feature space reconstruction loss to reduce dependencies on the target variable. 3). A new {\epsilon}-greedy strategy is used, incorporating insights from the pseudo labels to make the feature selection process more effective.