 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgek-Mixup Regularization for Deep Learning via Optimal Transport
Paper and Code

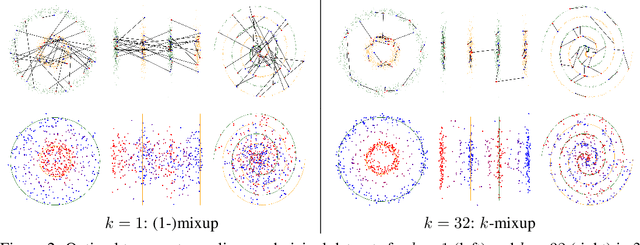

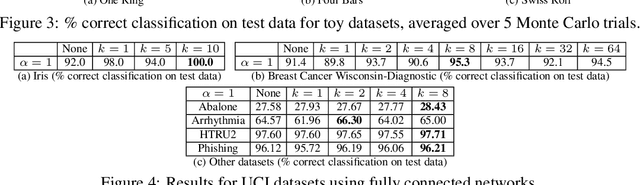
Mixup is a popular regularization technique for training deep neural networks that can improve generalization and increase adversarial robustness. It perturbs input training data in the direction of other randomly-chosen instances in the training set. To better leverage the structure of the data, we extend mixup to \emph{$k$-mixup} by perturbing $k$-batches of training points in the direction of other $k$-batches using displacement interpolation, interpolation under the Wasserstein metric. We demonstrate theoretically and in simulations that $k$-mixup preserves cluster and manifold structures, and we extend theory studying efficacy of standard mixup. Our empirical results show that training with $k$-mixup further improves generalization and robustness on benchmark datasets.