 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK For The Price Of 1: Parameter Efficient Multi-task And Transfer Learning
Paper and Code
Oct 25, 2018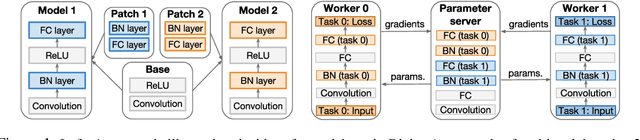

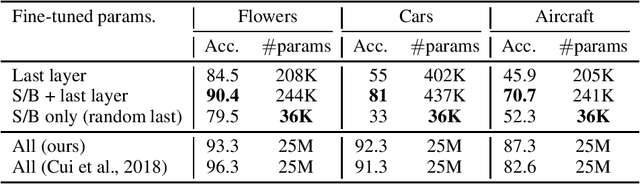
We introduce a novel method that enables parameter-efficient transfer and multitask learning. The basic approach is to allow a model patch - a small set of parameters - to specialize to each task, instead of fine-tuning the last layer or the entire network. For instance, we show that learning a set of scales and biases allows a network to learn a completely different embedding that could be used for different tasks (such as converting an SSD detection model into a 1000-class classification model while reusing 98% of parameters of the feature extractor). Similarly, we show that re-learning the existing low-parameter layers (such as depth-wise convolutions) also improves accuracy significantly. Our approach allows both simultaneous (multi-task) learning as well as sequential transfer learning wherein we adapt pretrained networks to solve new problems. For multi-task learning, despite using much fewer parameters than traditional logits-only fine-tuning, we match single-task-based performance.