 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Generative and Contrastive Learning for Unsupervised Person Re-identification
Paper and Code
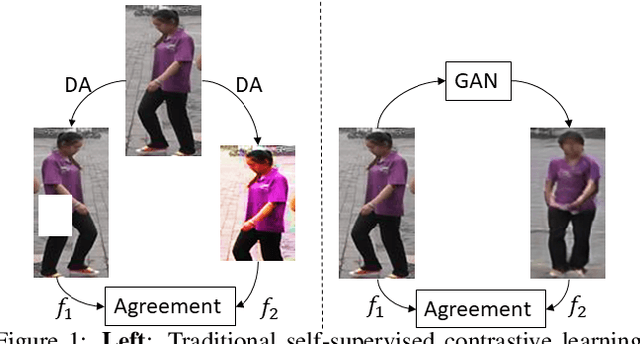

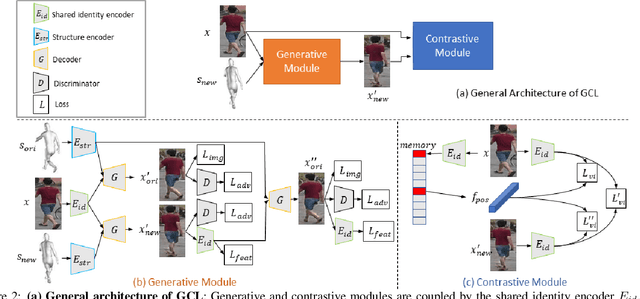

Annotating identity labels in large-scale datasets is a labour-intensive work, which strongly limits the scalability of person re-identification (ReID) in the real world. Unsupervised ReID addresses this issue by learning representations directly from unlabeled images. Recent self-supervised contrastive learning provides an effective approach for unsupervised representation learning. In this paper, we incorporate a Generative Adversarial Network (GAN) and contrastive learning into one joint training framework. While the GAN provides online data augmentation for contrastive learning, the contrastive module learns view-invariant features for generation. In this context, we propose a mesh-based novel view generator. Specifically, mesh projections serve as references towards generating novel views of a person. In addition, we propose a view-invariant loss to facilitate contrastive learning between original and generated views. Deviating from previous GAN-based unsupervised ReID methods involving domain adaptation, we do not rely on a labeled source dataset, which makes our method more flexible. Extensive experimental results show that our method significantly outperforms state-of-the-art methods under both, fully unsupervised and unsupervised domain adaptive settings on several large scale ReID datsets.