 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Generalisation in Continuous Deep Reinforcement Learning
Paper and Code
Feb 20, 2019


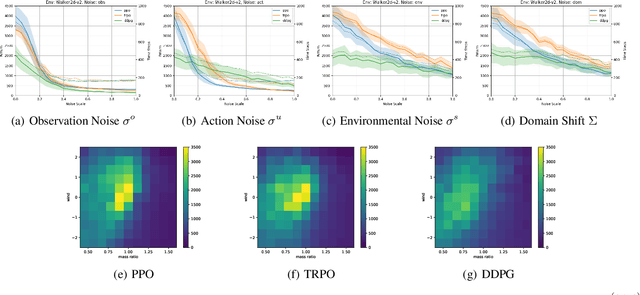
Deep Reinforcement Learning has shown great success in a variety of control tasks. However, it is unclear how close we are to the vision of putting Deep RL into practice to solve real world problems. In particular, common practice in the field is to train policies on largely deterministic simulators and to evaluate algorithms through training performance alone, without a train/test distinction to ensure models generalise and are not overfitted. Moreover, it is not standard practice to check for generalisation under domain shift, although robustness to such system change between training and testing would be necessary for real-world Deep RL control, for example, in robotics. In this paper we study these issues by first characterising the sources of uncertainty that provide generalisation challenges in Deep RL. We then provide a new benchmark and thorough empirical evaluation of generalisation challenges for state of the art Deep RL methods. In particular, we show that, if generalisation is the goal, then common practice of evaluating algorithms based on their training performance leads to the wrong conclusions about algorithm choice. Finally, we evaluate several techniques for improving generalisation and draw conclusions about the most robust techniques to date.