 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Models for Causal Transfer Learning
Paper and Code
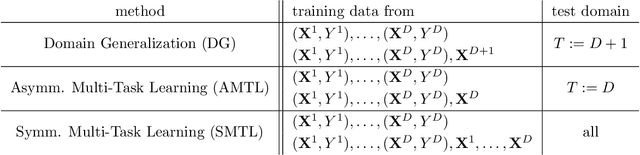
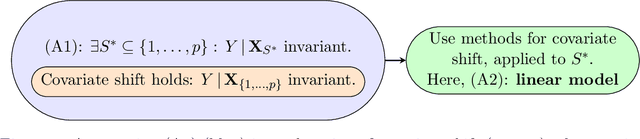
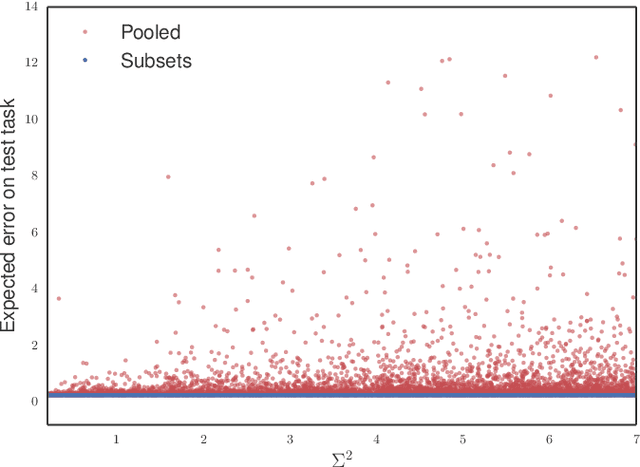

Methods of transfer learning try to combine knowledge from several related tasks (or domains) to improve performance on a test task. Inspired by causal methodology, we relax the usual covariate shift assumption and assume that it holds true for a subset of predictor variables: the conditional distribution of the target variable given this subset of predictors is invariant over all tasks. We show how this assumption can be motivated from ideas in the field of causality. We focus on the problem of Domain Generalization, in which no examples from the test task are observed. We prove that in an adversarial setting using this subset for prediction is optimal in Domain Generalization; we further provide examples, in which the tasks are sufficiently diverse and the estimator therefore outperforms pooling the data, even on average. If examples from the test task are available, we also provide a method to transfer knowledge from the training tasks and exploit all available features for prediction. However, we provide no guarantees for this method. We introduce a practical method which allows for automatic inference of the above subset and provide corresponding code. We present results on synthetic data sets and a gene deletion data set.