 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Convolutional Neural Networks for Effective Translation Initiation Site Prediction
Paper and Code
Nov 27, 2017

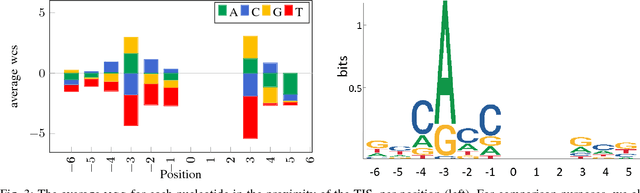
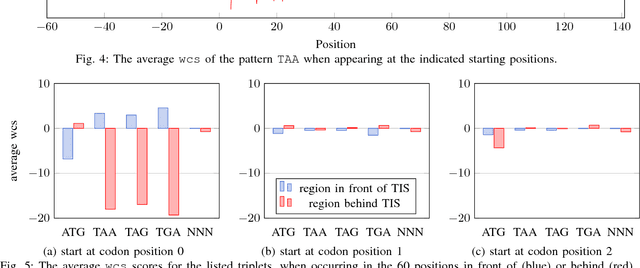
Thanks to rapidly evolving sequencing techniques, the amount of genomic data at our disposal is growing increasingly large. Determining the gene structure is a fundamental requirement to effectively interpret gene function and regulation. An important part in that determination process is the identification of translation initiation sites. In this paper, we propose a novel approach for automatic prediction of translation initiation sites, leveraging convolutional neural networks that allow for automatic feature extraction. Our experimental results demonstrate that we are able to improve the state-of-the-art approaches with a decrease of 75.2% in false positive rate and with a decrease of 24.5% in error rate on chosen datasets. Furthermore, an in-depth analysis of the decision-making process used by our predictive model shows that our neural network implicitly learns biologically relevant features from scratch, without any prior knowledge about the problem at hand, such as the Kozak consensus sequence, the influence of stop and start codons in the sequence and the presence of donor splice site patterns. In summary, our findings yield a better understanding of the internal reasoning of a convolutional neural network when applying such a neural network to genomic data.