 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Image Synthesis with Panoptic Layout Generation
Paper and Code
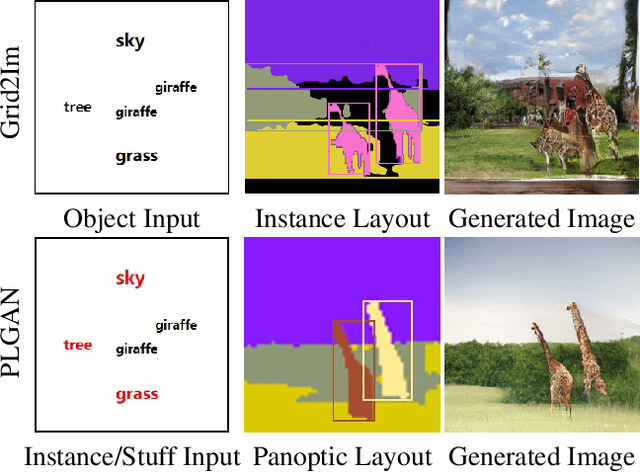
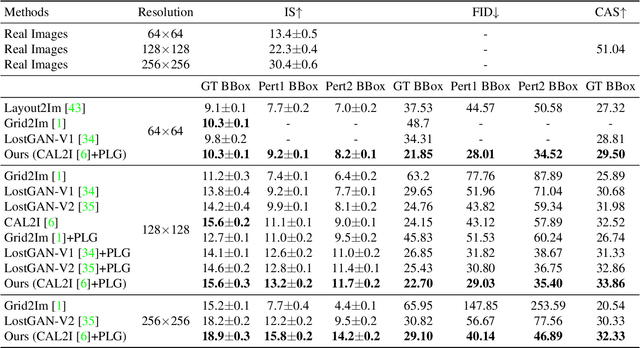
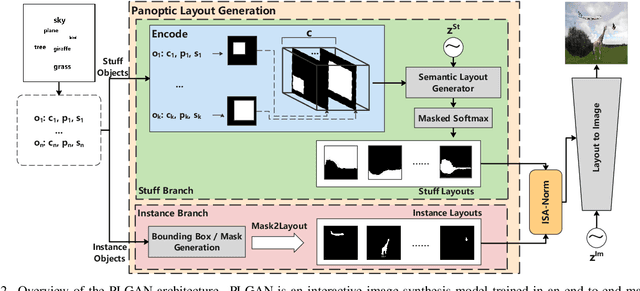

Interactive image synthesis from user-guided input is a challenging task when users wish to control the scene structure of a generated image with ease.Although remarkable progress has been made on layout-based image synthesis approaches, in order to get realistic fake image in interactive scene, existing methods require high-precision inputs, which probably need adjustment several times and are unfriendly to novice users. When placement of bounding boxes is subject to perturbation, layout-based models suffer from "missing regions" in the constructed semantic layouts and hence undesirable artifacts in the generated images. In this work, we propose Panoptic Layout Generative Adversarial Networks (PLGAN) to address this challenge. The PLGAN employs panoptic theory which distinguishes object categories between "stuff" with amorphous boundaries and "things" with well-defined shapes, such that stuff and instance layouts are constructed through separate branches and later fused into panoptic layouts. In particular, the stuff layouts can take amorphous shapes and fill up the missing regions left out by the instance layouts. We experimentally compare our PLGAN with state-of-the-art layout-based models on the COCO-Stuff, Visual Genome, and Landscape datasets. The advantages of PLGAN are not only visually demonstrated but quantitatively verified in terms of inception score, Fr\'echet inception distance, classification accuracy score, and coverage.