 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Theoretic Measures for Fairness-aware Feature Selection
Paper and Code
Jun 08, 2021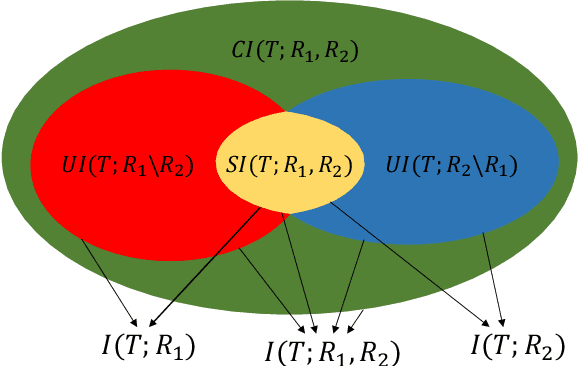
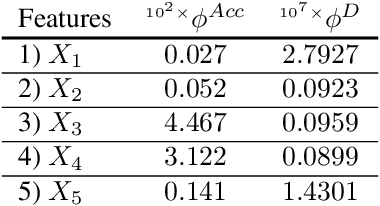
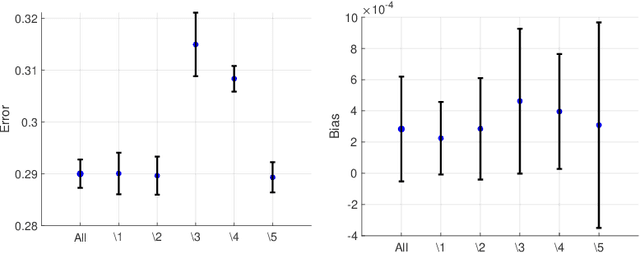
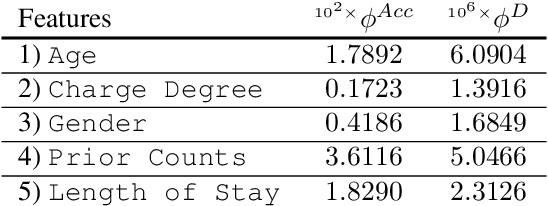
Machine learning algorithms are increasingly used for consequential decision making regarding individuals based on their relevant features. Features that are relevant for accurate decisions may however lead to either explicit or implicit forms of discrimination against unprivileged groups, such as those of certain race or gender. This happens due to existing biases in the training data, which are often replicated or even exacerbated by the learning algorithm. Identifying and measuring these biases at the data level is a challenging problem due to the interdependence among the features, and the decision outcome. In this work, we develop a framework for fairness-aware feature selection which takes into account the correlation among the features and the decision outcome, and is based on information theoretic measures for the accuracy and discriminatory impacts of features. In particular, we first propose information theoretic measures which quantify the impact of different subsets of features on the accuracy and discrimination of the decision outcomes. We then deduce the marginal impact of each feature using Shapley value function; a solution concept in cooperative game theory used to estimate marginal contributions of players in a coalitional game. Finally, we design a fairness utility score for each feature (for feature selection) which quantifies how this feature influences accurate as well as nondiscriminatory decisions. Our framework depends on the joint statistics of the data rather than a particular classifier design. We examine our proposed framework on real and synthetic data to evaluate its performance.