 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference in Multi-Layer Networks with Matrix-Valued Unknowns
Paper and Code
Jan 26, 2020

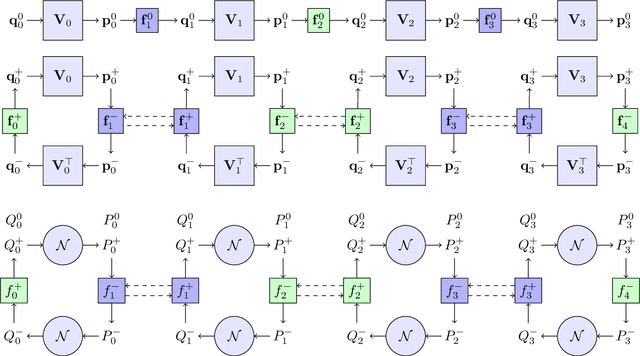
We consider the problem of inferring the input and hidden variables of a stochastic multi-layer neural network from an observation of the output. The hidden variables in each layer are represented as matrices. This problem applies to signal recovery via deep generative prior models, multi-task and mixed regression and learning certain classes of two-layer neural networks. A unified approximation algorithm for both MAP and MMSE inference is proposed by extending a recently-developed Multi-Layer Vector Approximate Message Passing (ML-VAMP) algorithm to handle matrix-valued unknowns. It is shown that the performance of the proposed Multi-Layer Matrix VAMP (ML-Mat-VAMP) algorithm can be exactly predicted in a certain random large-system limit, where the dimensions $N\times d$ of the unknown quantities grow as $N\rightarrow\infty$ with $d$ fixed. In the two-layer neural-network learning problem, this scaling corresponds to the case where the number of input features and training samples grow to infinity but the number of hidden nodes stays fixed. The analysis enables a precise prediction of the parameter and test error of the learning.