Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Adversarial Robustness of NLP Models by Information Bottleneck
Paper and Code
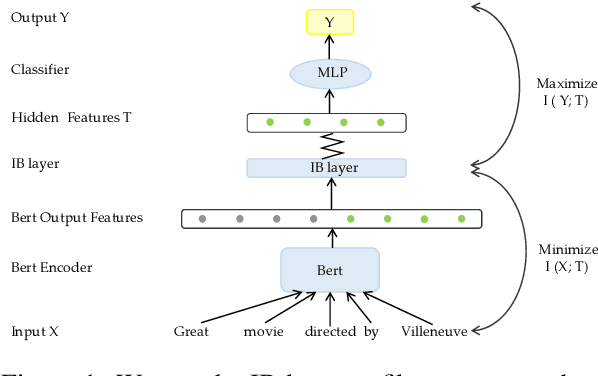
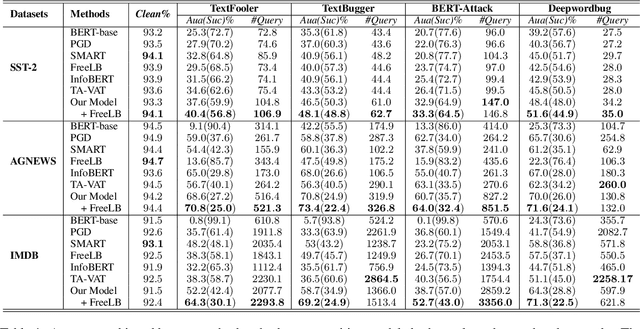
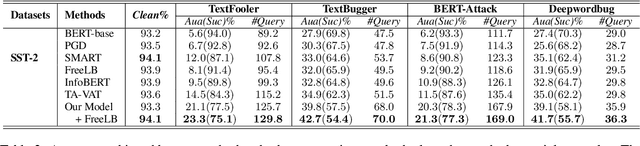

Existing studies have demonstrated that adversarial examples can be directly attributed to the presence of non-robust features, which are highly predictive, but can be easily manipulated by adversaries to fool NLP models. In this study, we explore the feasibility of capturing task-specific robust features, while eliminating the non-robust ones by using the information bottleneck theory. Through extensive experiments, we show that the models trained with our information bottleneck-based method are able to achieve a significant improvement in robust accuracy, exceeding performances of all the previously reported defense methods while suffering almost no performance drop in clean accuracy on SST-2, AGNEWS and IMDB datasets.
* Findings of the Association for Computational Linguistics: ACL
2022, 3588-3598
View paper on