 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Spatial Codification in Semantic Segmentation
Paper and Code
May 27, 2015


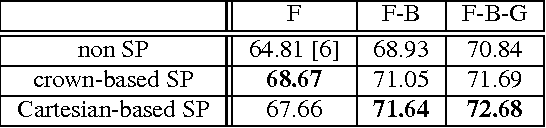
This paper explores novel approaches for improving the spatial codification for the pooling of local descriptors to solve the semantic segmentation problem. We propose to partition the image into three regions for each object to be described: Figure, Border and Ground. This partition aims at minimizing the influence of the image context on the object description and vice versa by introducing an intermediate zone around the object contour. Furthermore, we also propose a richer visual descriptor of the object by applying a Spatial Pyramid over the Figure region. Two novel Spatial Pyramid configurations are explored: Cartesian-based and crown-based Spatial Pyramids. We test these approaches with state-of-the-art techniques and show that they improve the Figure-Ground based pooling in the Pascal VOC 2011 and 2012 semantic segmentation challenges.