 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving RNN Transducer Based ASR with Auxiliary Tasks
Paper and Code
Nov 09, 2020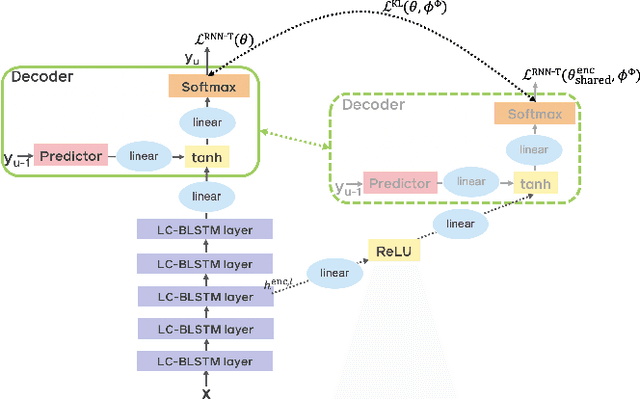
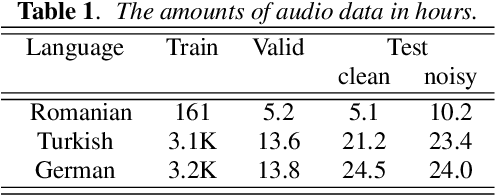
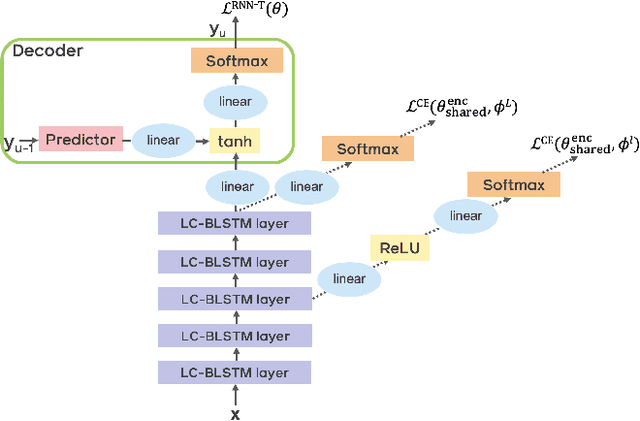
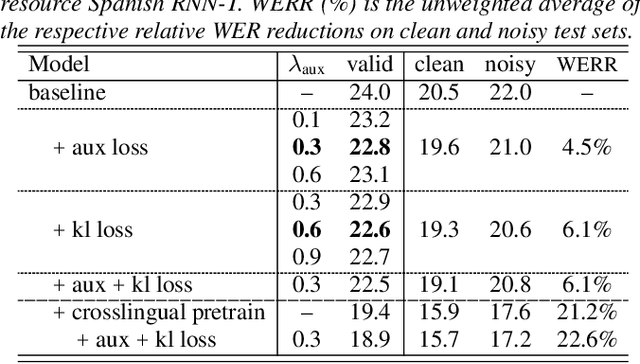
End-to-end automatic speech recognition (ASR) models with a single neural network have recently demonstrated state-of-the-art results compared to conventional hybrid speech recognizers. Specifically, recurrent neural network transducer (RNN-T) has shown competitive ASR performance on various benchmarks. In this work, we examine ways in which RNN-T can achieve better ASR accuracy via performing auxiliary tasks. We propose (i) using the same auxiliary task as primary RNN-T ASR task, and (ii) performing context-dependent graphemic state prediction as in conventional hybrid modeling. In transcribing social media videos with varying training data size, we first evaluate the streaming ASR performance on three languages: Romanian, Turkish and German. We find that both proposed methods provide consistent improvements. Next, we observe that both auxiliary tasks demonstrate efficacy in learning deep transformer encoders for RNN-T criterion, thus achieving competitive results - 2.0%/4.2% WER on LibriSpeech test-clean/other - as compared to prior top performing models.