 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving non-autoregressive end-to-end speech recognition with pre-trained acoustic and language models
Paper and Code
Jan 26, 2022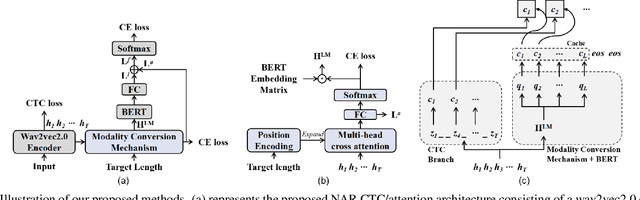
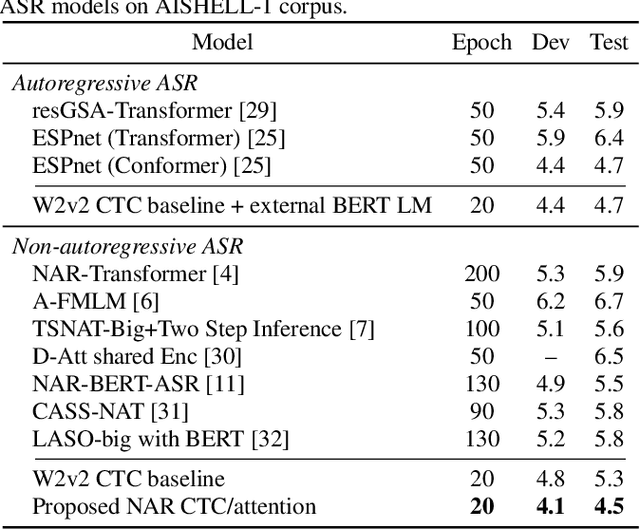
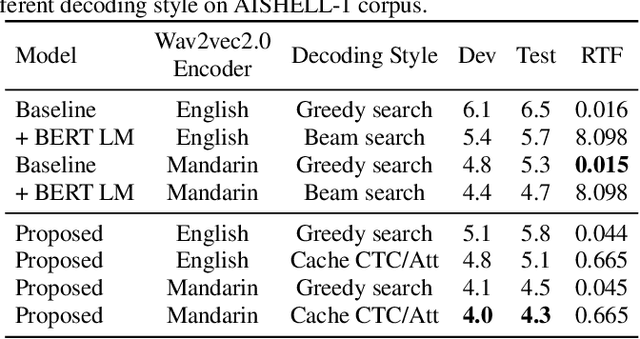
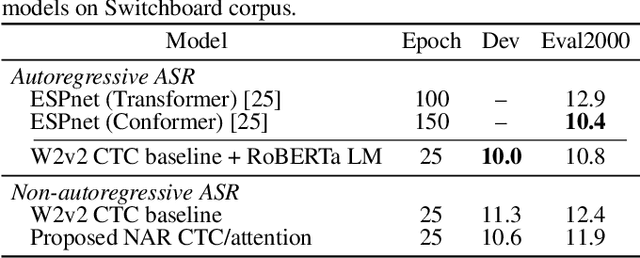
While Transformers have achieved promising results in end-to-end (E2E) automatic speech recognition (ASR), their autoregressive (AR) structure becomes a bottleneck for speeding up the decoding process. For real-world deployment, ASR systems are desired to be highly accurate while achieving fast inference. Non-autoregressive (NAR) models have become a popular alternative due to their fast inference speed, but they still fall behind AR systems in recognition accuracy. To fulfill the two demands, in this paper, we propose a NAR CTC/attention model utilizing both pre-trained acoustic and language models: wav2vec2.0 and BERT. To bridge the modality gap between speech and text representations obtained from the pre-trained models, we design a novel modality conversion mechanism, which is more suitable for logographic languages. During inference, we employ a CTC branch to generate a target length, which enables the BERT to predict tokens in parallel. We also design a cache-based CTC/attention joint decoding method to improve the recognition accuracy while keeping the decoding speed fast. Experimental results show that the proposed NAR model greatly outperforms our strong wav2vec2.0 CTC baseline (15.1% relative CER reduction on AISHELL-1). The proposed NAR model significantly surpasses previous NAR systems on the AISHELL-1 benchmark and shows a potential for English tasks.