 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Few-shot Text Classification via Pretrained Language Representations
Paper and Code
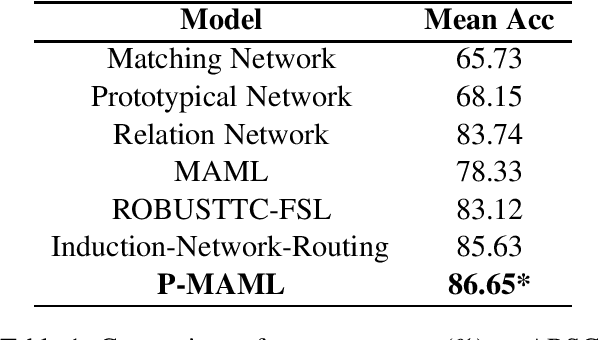

Text classification tends to be difficult when the data is deficient or when it is required to adapt to unseen classes. In such challenging scenarios, recent studies have often used meta-learning to simulate the few-shot task, thus negating explicit common linguistic features across tasks. Deep language representations have proven to be very effective forms of unsupervised pretraining, yielding contextualized features that capture linguistic properties and benefit downstream natural language understanding tasks. However, the effect of pretrained language representation for few-shot learning on text classification tasks is still not well understood. In this study, we design a few-shot learning model with pretrained language representations and report the empirical results. We show that our approach is not only simple but also produces state-of-the-art performance on a well-studied sentiment classification dataset. It can thus be further suggested that pretraining could be a promising solution for few shot learning of many other NLP tasks. The code and the dataset to replicate the experiments are made available at https://github.com/zxlzr/FewShotNLP.