 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Consistency Training for Semi-Supervised Sequence-to-Sequence ASR via Speech Chain Reconstruction and Self-Transcribing
Paper and Code
May 14, 2022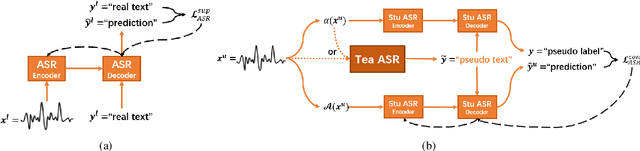
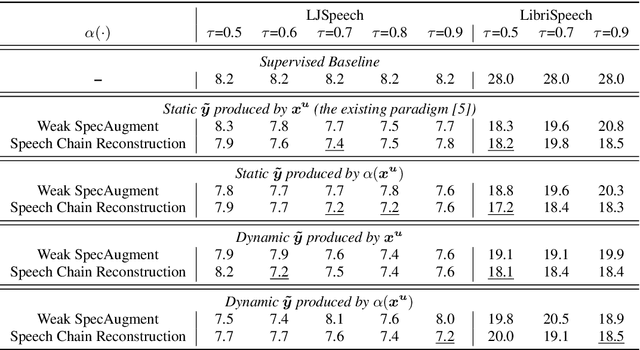
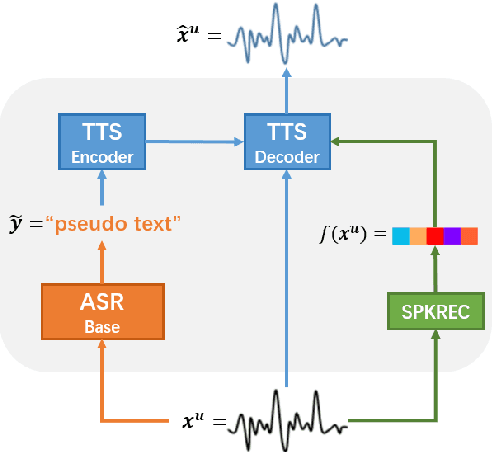
Consistency regularization has recently been applied to semi-supervised sequence-to-sequence (S2S) automatic speech recognition (ASR). This principle encourages an ASR model to output similar predictions for the same input speech with different perturbations. The existing paradigm of semi-supervised S2S ASR utilizes SpecAugment as data augmentation and requires a static teacher model to produce pseudo transcripts for untranscribed speech. However, this paradigm fails to take full advantage of consistency regularization. First, the masking operations of SpecAugment may damage the linguistic contents of the speech, thus influencing the quality of pseudo labels. Second, S2S ASR requires both input speech and prefix tokens to make the next prediction. The static prefix tokens made by the offline teacher model cannot match dynamic pseudo labels during consistency training. In this work, we propose an improved consistency training paradigm of semi-supervised S2S ASR. We utilize speech chain reconstruction as the weak augmentation to generate high-quality pseudo labels. Moreover, we demonstrate that dynamic pseudo transcripts produced by the student ASR model benefit the consistency training. Experiments on LJSpeech and LibriSpeech corpora show that compared to supervised baselines, our improved paradigm achieves a 12.2% CER improvement in the single-speaker setting and 38.6% in the multi-speaker setting.