 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Algorithms for Conservative Exploration in Bandits
Paper and Code
Feb 08, 2020
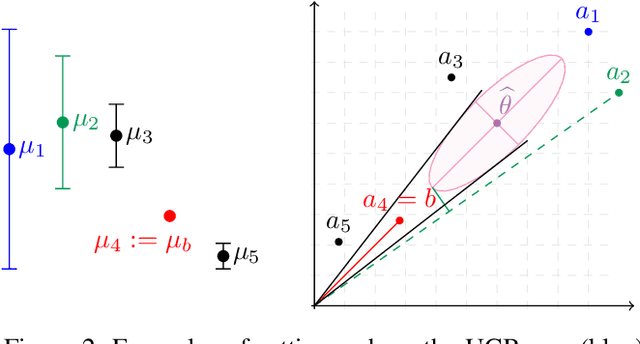

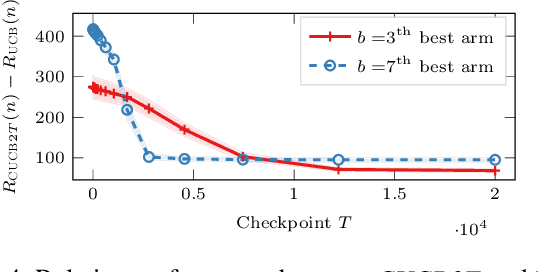
In many fields such as digital marketing, healthcare, finance, and robotics, it is common to have a well-tested and reliable baseline policy running in production (e.g., a recommender system). Nonetheless, the baseline policy is often suboptimal. In this case, it is desirable to deploy online learning algorithms (e.g., a multi-armed bandit algorithm) that interact with the system to learn a better/optimal policy under the constraint that during the learning process the performance is almost never worse than the performance of the baseline itself. In this paper, we study the conservative learning problem in the contextual linear bandit setting and introduce a novel algorithm, the Conservative Constrained LinUCB (CLUCB2). We derive regret bounds for CLUCB2 that match existing results and empirically show that it outperforms state-of-the-art conservative bandit algorithms in a number of synthetic and real-world problems. Finally, we consider a more realistic constraint where the performance is verified only at predefined checkpoints (instead of at every step) and show how this relaxed constraint favorably impacts the regret and empirical performance of CLUCB2.