 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove the Evaluation of Fluency Using Entropy for Machine Translation Evaluation Metrics
Paper and Code
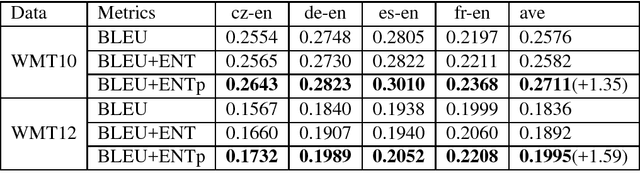

The widely-used automatic evaluation metrics cannot adequately reflect the fluency of the translations. The n-gram-based metrics, like BLEU, limit the maximum length of matched fragments to n and cannot catch the matched fragments longer than n, so they can only reflect the fluency indirectly. METEOR, which is not limited by n-gram, uses the number of matched chunks but it does not consider the length of each chunk. In this paper, we propose an entropy-based method, which can sufficiently reflect the fluency of translations through the distribution of matched words. This method can easily combine with the widely-used automatic evaluation metrics to improve the evaluation of fluency. Experiments show that the correlations of BLEU and METEOR are improved on sentence level after combining with the entropy-based method on WMT 2010 and WMT 2012.