 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance Weighted Policy Learning and Adaption
Paper and Code
Sep 10, 2020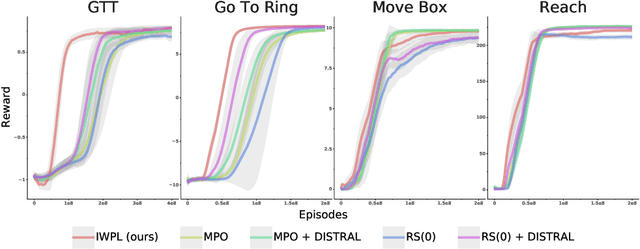
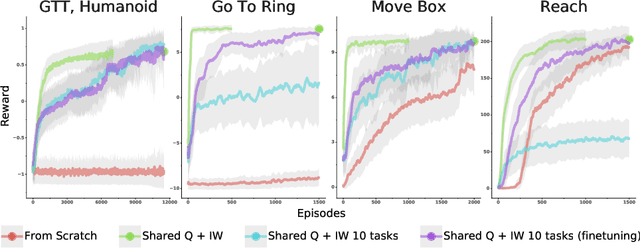

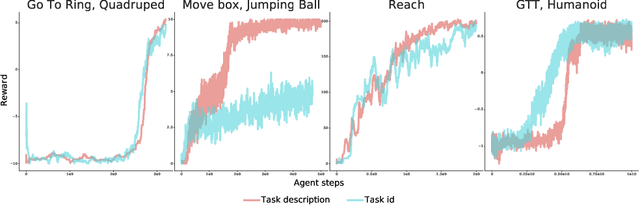
The ability to exploit prior experience to solve novel problems rapidly is a hallmark of biological learning systems and of great practical importance for artificial ones. In the meta reinforcement learning literature much recent work has focused on the problem of optimizing the learning process itself. In this paper we study a complementary approach which is conceptually simple, general, modular and built on top of recent improvements in off-policy learning. The framework is inspired by ideas from the probabilistic inference literature and combines robust off-policy learning with a behavior prior, or default behavior that constrains the space of solutions and serves as a bias for exploration; as well as a representation for the value function, both of which are easily learned from a number of training tasks in a multi-task scenario. Our approach achieves competitive adaptation performance on hold-out tasks compared to meta reinforcement learning baselines and can scale to complex sparse-reward scenarios.