 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIBD: Alleviating Hallucinations in Large Vision-Language Models via Image-Biased Decoding
Paper and Code
Feb 28, 2024

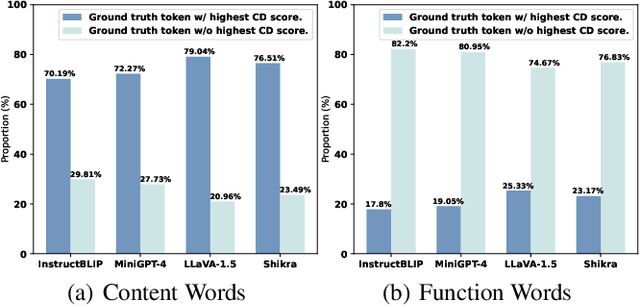

Despite achieving rapid developments and with widespread applications, Large Vision-Language Models (LVLMs) confront a serious challenge of being prone to generating hallucinations. An over-reliance on linguistic priors has been identified as a key factor leading to these hallucinations. In this paper, we propose to alleviate this problem by introducing a novel image-biased decoding (IBD) technique. Our method derives the next-token probability distribution by contrasting predictions from a conventional LVLM with those of an image-biased LVLM, thereby amplifying the correct information highly correlated with image content while mitigating the hallucinatory errors caused by excessive dependence on text. We further conduct a comprehensive statistical analysis to validate the reliability of our method, and design an adaptive adjustment strategy to achieve robust and flexible handling under varying conditions. Experimental results across multiple evaluation metrics verify that our method, despite not requiring additional training data and only with a minimal increase in model parameters, can significantly reduce hallucinations in LVLMs and enhance the truthfulness of the generated response.