 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYDRA: Hypergradient Data Relevance Analysis for Interpreting Deep Neural Networks
Paper and Code
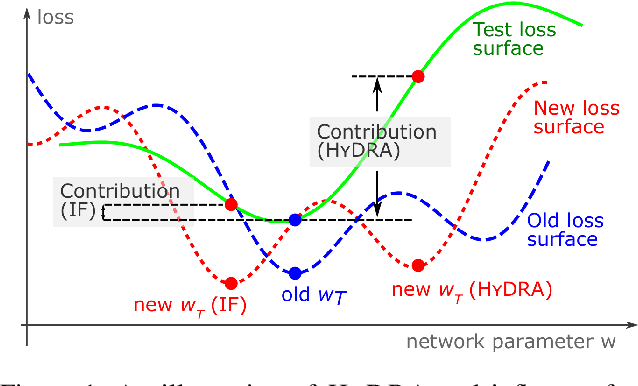



The behaviors of deep neural networks (DNNs) are notoriously resistant to human interpretations. In this paper, we propose Hypergradient Data Relevance Analysis, or HYDRA, which interprets the predictions made by DNNs as effects of their training data. Existing approaches generally estimate data contributions around the final model parameters and ignore how the training data shape the optimization trajectory. By unrolling the hypergradient of test loss w.r.t. the weights of training data, HYDRA assesses the contribution of training data toward test data points throughout the training trajectory. In order to accelerate computation, we remove the Hessian from the calculation and prove that, under moderate conditions, the approximation error is bounded. Corroborating this theoretical claim, empirical results indicate the error is indeed small. In addition, we quantitatively demonstrate that HYDRA outperforms influence functions in accurately estimating data contribution and detecting noisy data labels. The source code is available at https://github.com/cyyever/aaai_hydra_8686.