 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHVTR: Hybrid Volumetric-Textural Rendering for Human Avatars
Paper and Code


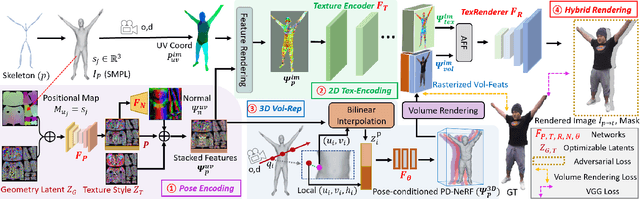

We propose a novel neural rendering pipeline, Hybrid Volumetric-Textural Rendering (HVTR), which synthesizes virtual human avatars from arbitrary poses efficiently and at high quality. First, we learn to encode articulated human motions on a dense UV manifold of the human body surface. To handle complicated motions (e.g., self-occlusions), we then leverage the encoded information on the UV manifold to construct a 3D volumetric representation based on a dynamic pose-conditioned neural radiance field. While this allows us to represent 3D geometry with changing topology, volumetric rendering is computationally heavy. Hence we employ only a rough volumetric representation using a pose-conditioned downsampled neural radiance field (PD-NeRF), which we can render efficiently at low resolutions. In addition, we learn 2D textural features that are fused with rendered volumetric features in image space. The key advantage of our approach is that we can then convert the fused features into a high resolution, high-quality avatar by a fast GAN-based textural renderer. We demonstrate that hybrid rendering enables HVTR to handle complicated motions, render high-quality avatars under user-controlled poses/shapes and even loose clothing, and most importantly, be fast at inference time. Our experimental results also demonstrate state-of-the-art quantitative results.