 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-In-The-Loop Document Layout Analysis
Paper and Code
Aug 04, 2021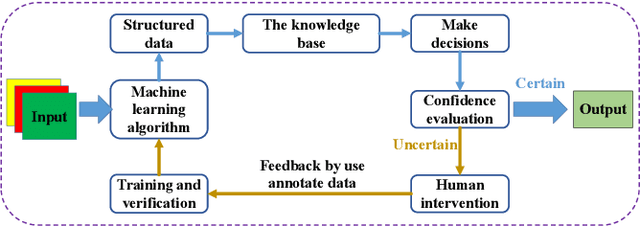
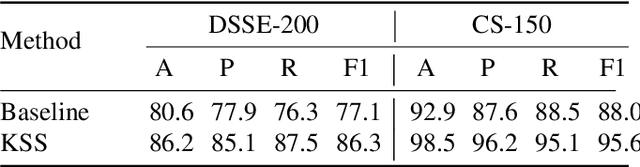
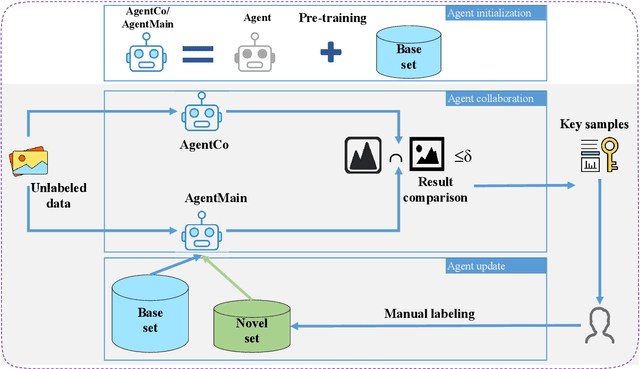
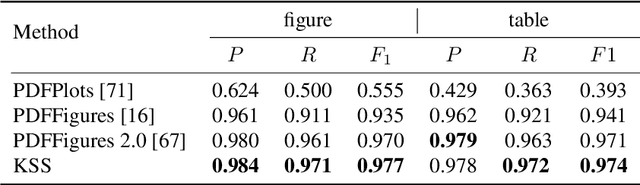
Document layout analysis (DLA) aims to divide a document image into different types of regions. DLA plays an important role in the document content understanding and information extraction systems. Exploring a method that can use less data for effective training contributes to the development of DLA. We consider a Human-in-the-loop (HITL) collaborative intelligence in the DLA. Our approach was inspired by the fact that the HITL push the model to learn from the unknown problems by adding a small amount of data based on knowledge. The HITL select key samples by using confidence. However, using confidence to find key samples is not suitable for DLA tasks. We propose the Key Samples Selection (KSS) method to find key samples in high-level tasks (semantic segmentation) more accurately through agent collaboration, effectively reducing costs. Once selected, these key samples are passed to human beings for active labeling, then the model will be updated with the labeled samples. Hence, we revisited the learning system from reinforcement learning and designed a sample-based agent update strategy, which effectively improves the agent's ability to accept new samples. It achieves significant improvement results in two benchmarks (DSSE-200 (from 77.1% to 86.3%) and CS-150 (from 88.0% to 95.6%)) by using 10% of labeled data.