 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Put Users in Control of their Data via Federated Pair-Wise Recommendation
Paper and Code
Aug 17, 2020

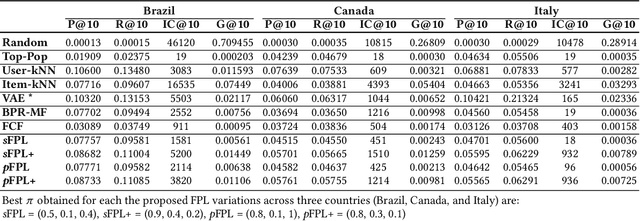

Recommendation services are extensively adopted in several user-centered applications as a tool to alleviate the information overload problem and help users in orienteering in a vast space of possible choices. In such scenarios, privacy is a crucial concern since users may not be willing to share their sensitive preferences (e.g., visited locations, read books, bought items) with a central server. Unfortunately, data harvesting and collection is at the basis of modern, state-of-the-art approaches to recommendation. Decreased users' willingness to share personal information along with data minimization/protection policies (such as the European GDPR), can result in the "data scarcity" dilemma affecting data-intensive applications such as recommender systems (RS). We argue that scarcity of adequate data due to privacy concerns can severely impair the quality of learned models and, in the long term, result in a turnover and disloyal customers with direct consequences for lives, society, and businesses. To address these issues, we present FPL, an architecture in which users collaborate in training a central factorization model while controlling the amount of sensitive data leaving their devices. The proposed approach implements pair-wise learning to rank optimization by following the Federated Learning principles conceived originally to mitigate the privacy risks of traditional machine learning. We have conducted an extensive experimental evaluation on three Foursquare datasets and have verified the effectiveness of the proposed architecture concerning accuracy and beyond-accuracy objectives. We have analyzed the impact of communication cost with the central server on the system's performance, by varying the amount of local computation and training parallelism. Finally, we have carefully examined the impact of disclosed users' information on the quality of the final model and ...